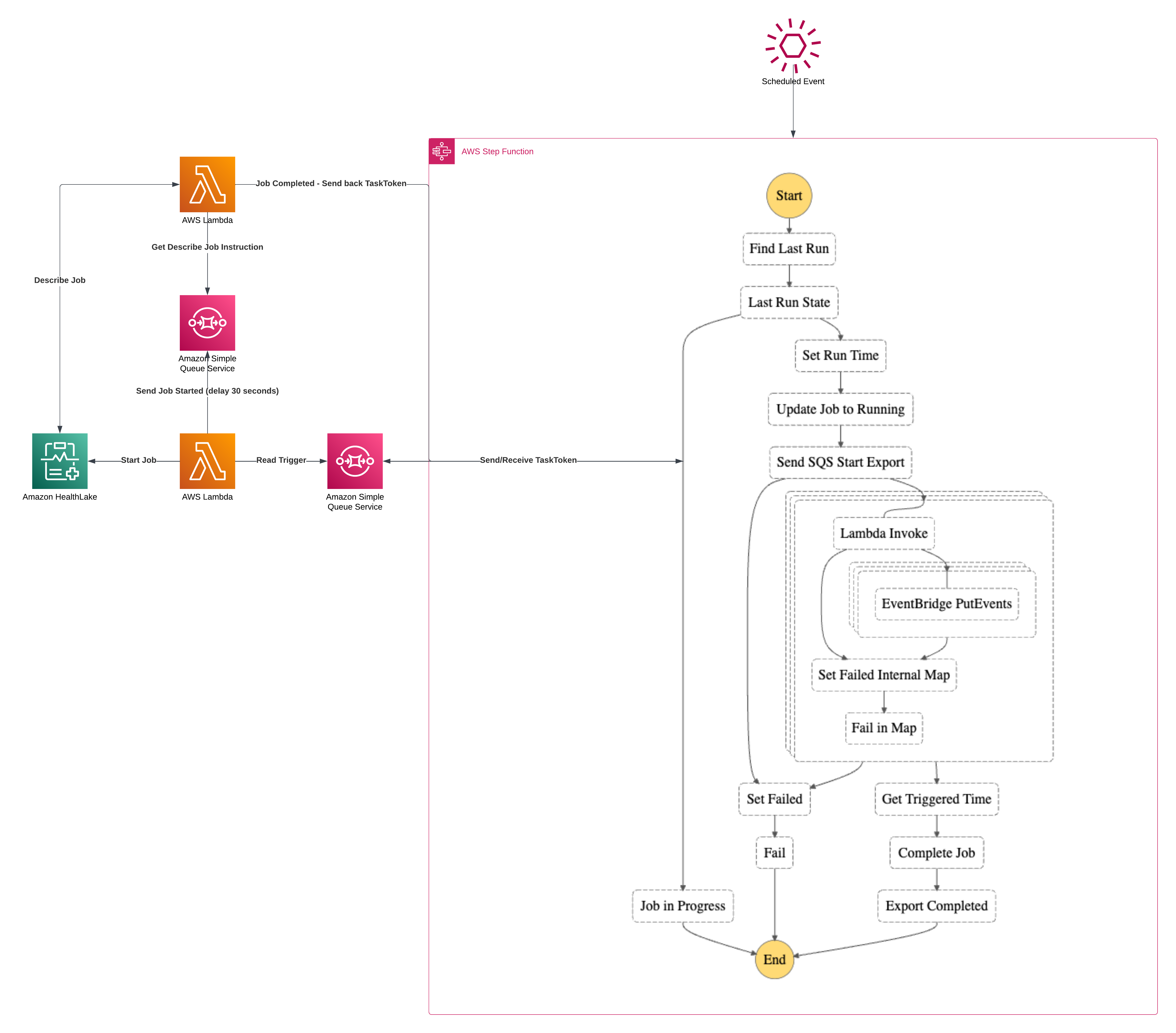
I’ve written a few articles lately on EventBridge Pipes and specifically around using them with DynamoDB Streams. I’ve written about Enrichment. And I’ve written about just straight Streaming. I believe that using EventBridge Pipes plays a nice part in a Serverless, Event-Driven approach. So in this article, I want to explore Streaming DynamoDB to EventBridge Pipes with multiple items in one table.
Several of the comments I received about Streaming DynamoDB to EventBridge Pipes were around, “What if I have multiple item collections in the same table?”. I intend to show a pattern for handling that exact problem in this article. At the bottom, you’ll find a working code sample that you can deploy and build on top of. I’ve used this exact setup in production, so rest assured that this is a great base to start from.