

Building Serverless applications can feel a bit overwhelming when you are first getting started. Sure, Event-Driven Systems have been around for many years but this notion of using managed services to “assemble” solutions vs a more traditional “plugin” style architecture might throw you for a loop. Continuing in the series of Building Serverless Applications with AWS, let’s have a look at the “Handling Events” aspect.
Series Topics
- Data Storage Choices
- Building the Application (Fargate/Containers vs Lambda)
- Handling Events
- Exposing the API (if there is one)
- Securing it all, including the API
- Debugging and Troubleshooting in Production
Handling Events
I feel like this is the top of the mountain in the Serverless ecosystem. The previous two articles were appetizers, but when it comes to how to handle events, these services are the main course. They each come with their own use cases and gotchas but at the end of the day, you will have some flavor of them if you are to adopt a fully Serverless application. So fair warning, this is going to be a long one, but the content in here will be the heart of your Event-Driven Serverless Design
I’d like to first start with this. AWS and cloud providers did not invent the term “Event-Driven Architecture”. Queues, Topics, Streaming and Messaging have been around for a long time. Those of us who have needed to decouple producers and consumers to gain flexibility and scale have been using these building blocks in our architectures for years. Now what AWS specifically has done is made this so simple for an architect to include in your build that there’s almost no reason in my opinion that you shouldn’t be using one of these. Of course, there are always exceptions to this rule, but if you are starting your Serverless journey, you won’t need anything beyond these four.
As with the previous articles in this series, I’m going to walk you through what questions I ask, and what service I’d select if I answer the questions yes.
Simple Queue Service (SQS)
Small history lesson. Back in 2006 Jeff Bar wrote about the release of SQS and I’ve yet to see any Serverless design that didn’t include this product somewhere in its implementation.
What problems does SQS solve or questions I might ask myself about choosing SQS?
- Do I want to batch event processing up in a single pull?
- Do I want to be able to have one consumer processing a message or batch at one time?
- Are there delayed processing requirements? Meaning might I want a message to sit for n seconds before a worker picks it up?
- Is ordering important?
- Am I concerned with de-duplication?
- Are my requirements as simple as enqueue and dequeue?
- Will a Dead Letter Queue be enough to deal with failure and do I know how to handle those failures?
If your answers are yes to the above, SQS is your service. As AWS describes it:
Amazon Simple Queue Service (Amazon SQS) lets you send, store, and receive messages between software components at any volume, without losing messages or requiring other services to be available. – AWS
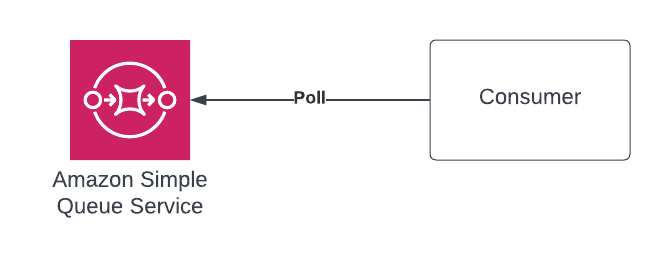
The bottom line on SQS is this. As Queue in architecture is there to decouple a producer and consumer. Its job is to allow an upstream component to generate messages at its own pace and then allow the downstream system to then consume and manage that pull success or pull failure as it sees fit. SQS does this super well and does it at a crazy scale all while the developer doesn’t care about the implementation.
You’ve got two types of SQS. Standard and FIFO. Standard does not guarantee order or deduplication. You will always get 1 copy of the message but you might get more, so your consumers should handle this and be idempotent. The other option is to run a FIFO queue which will dedupe messages and also allow ordering of such as well. So you get one guaranteed copy. With a standard queue, the scale is so out of my comprehension that I generally tell people for all intents and purposes, it’s infinitely scalable. I’ve read an AWS article that states performance greater than 100M messages dequeued per second. Which is just nuts.
Kinesis
Amazon Kinesis cost-effectively processes and analyzes streaming data at any scale as a fully managed service. With Kinesis, you can ingest real-time data, such as video, audio, application logs, website clickstreams, and IoT telemetry data, for machine learning (ML), analytics, and other application – AWS
You can think of Kinesis in a couple of ways.
First off, as a pure streaming data platform, you can publish and consume data just like you would with something like Kafka. I’m not going to begin to compare these two in this article, but again, the beauty of Kinesis is you’ll get so many features for feature parity without the need to build and manage servers. And yes, you can use MKS (Managed Kafka) but as a beginner and new Serverless developer, Kinesis will do you just fine.
Second, Kinesis comes in several flavors.
- Data Streams
- Firehose
- Data Analytics
- Video Streams
For the balance of this article, I’m going to be talking about Data Streams. The other flavors are sort of more nuanced versions which I don’t have as much experience in and would feel unprepared to discuss. Additionally, when comparing the other services, let’s assume that we are moving text (JSON) around our application.
The main three questions that I tend to answer yes to which leads me to Kinesis are these:
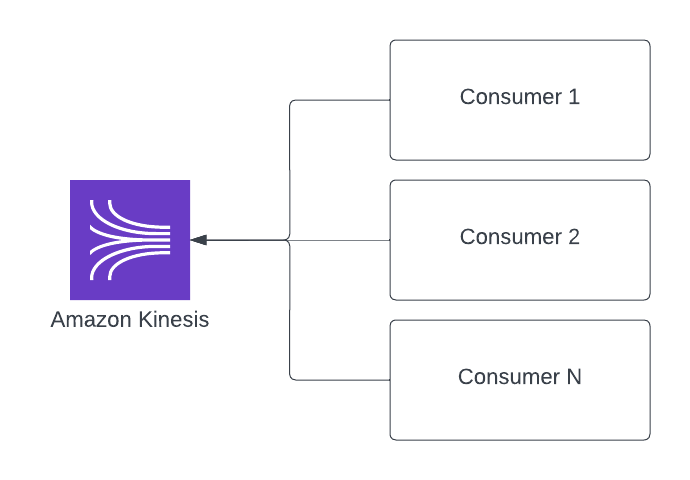
- Do I have multiple consumers that want to read the same message (this CAN be done with other services)
- Do I need to be able to replay the data?
- Is my need real-time or super close to it?
Simple Notification Service (SNS)
SNS is one of those services that has also been around for a while like SQS. Before things like EventBridge and Kinesis existed, the SNS->SQS pattern was a tried and true method for multi-casting events through your system. AWS describes SNS like this:
Amazon Simple Notification Service (Amazon SNS) sends notifications two ways, A2A and A2P. A2A provides high-throughput, push-based, many-to-many messaging between distributed systems, microservices, and event-driven serverless applications. These applications include Amazon Simple Queue Service (SQS), Amazon Kinesis Data Firehose, AWS Lambda, and other HTTPS endpoints. A2P functionality lets you send messages to your customers with SMS texts, push notifications, and email. – AWS
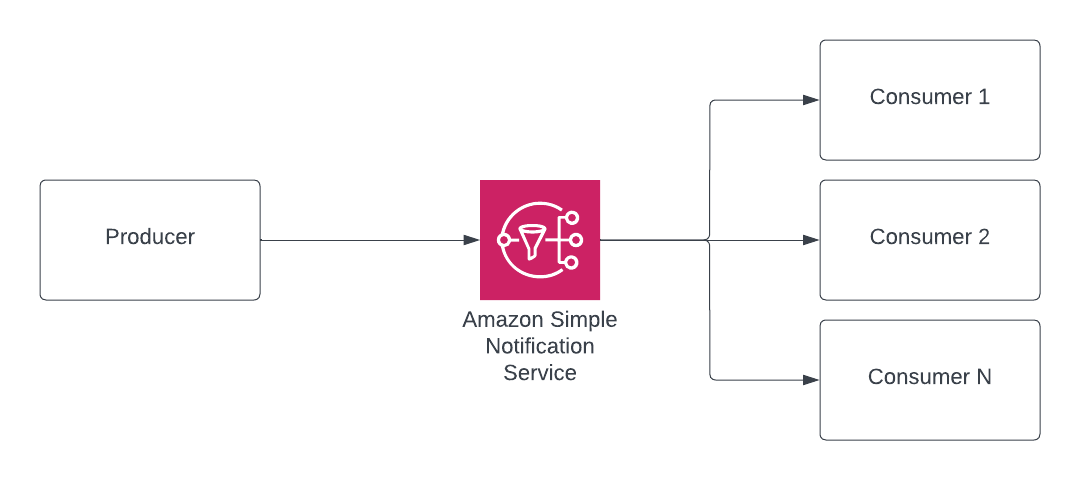
The first two services I’ve focused on the consumer side. And while you 100% can use SQS as an output for a producer as well as the input to a consumer, putting SNS in front of any SQS when dealing with producing events helps to decouple the two ends. For instance, if the producer knows about SNS and the consumer knows about SQS, then the producer and consumer don’t share any ties. The tie exists in the SNS->SQS subscription which can enable a 1:M relationship on producer->consumers. Secondary to that, Kinesis of course can be the output of a producer, but in the case of passing events in an EDA, generally SNS->SQS is a tried and true and simple way to go about things.
- Am I connecting one event to many events?
- Do all consumers get a copy of the same event?
In my current role as CTO, I helped implement a large SNS->SQS-based implementation 5 years ago and have been super happy with it. I mentioned above consumers get a copy of the same event and that’s mostly true, however, you can do some attribute and content level filtering in your subscriptions but I found it not as good as when working with EventBridge. I’m on the record at my company saying that if EventBridge was an option when I started this implementation, we’d be using that instead.
That doesn’t by any stretch mean that SNS is not an awesome service. Because it is and it can honestly do more than just push messages to SQS. So if you’ve got more than that or you like this super simple yet highly scalable approach, please don’t miss out on the goodness you can gain by putting SNS in your toolkit.
EventBridge
The last service to speak of when dealing with Serverless Events is EventBridge. Let me be a little more specific here, EventBridge is broken into 3 parts which makes it hard to compare in totality to SNS.
- Event Bus
- Pipes
- Scheduler
I’ll touch a bit more on the Pipes and Scheduler later on, but for now, Event Bus is the main player in shuttling and directing events on your platform.
Amazon EventBridge Event Bus is a serverless event bus that makes it easier to build event-driven applications at scale using events generated from your applications, third-party software-as-as-service (SaaS) applications, and AWS services. EventBridge Event Bus acts as an event router to route your events – completely decoupling your event sources and targets. You can create rules on the event bus to allow each subscriber to choose which events they want to consume. Rules can also handle routing, retries, and error handling. Using EventBridge Event Bus, you can build loosely coupled applications to enable your development teams to act more independently, speed up development time, and simplify making changes to your applications. – AWS
In a nutshell, what this means is that you have the power of an Event Router with filtering and traffic directing all in a Serverless package. You’ll find that the expressiveness of Rules and Targets to be a little more industrial than the SNS version and you can isolate things a little more fine-grained with things like Event Bus Meshes which is a pattern I explore in the linked article.
In fairness, my bias generally leads me to use EB over SNS in almost all cases, so if I was starting, I’d spend the time and invest in learning EventBridge and all 3 of its components which will make it your go-to publisher but then in the process, you’ll know when to use SNS which will have very specific use cases you want to solve.
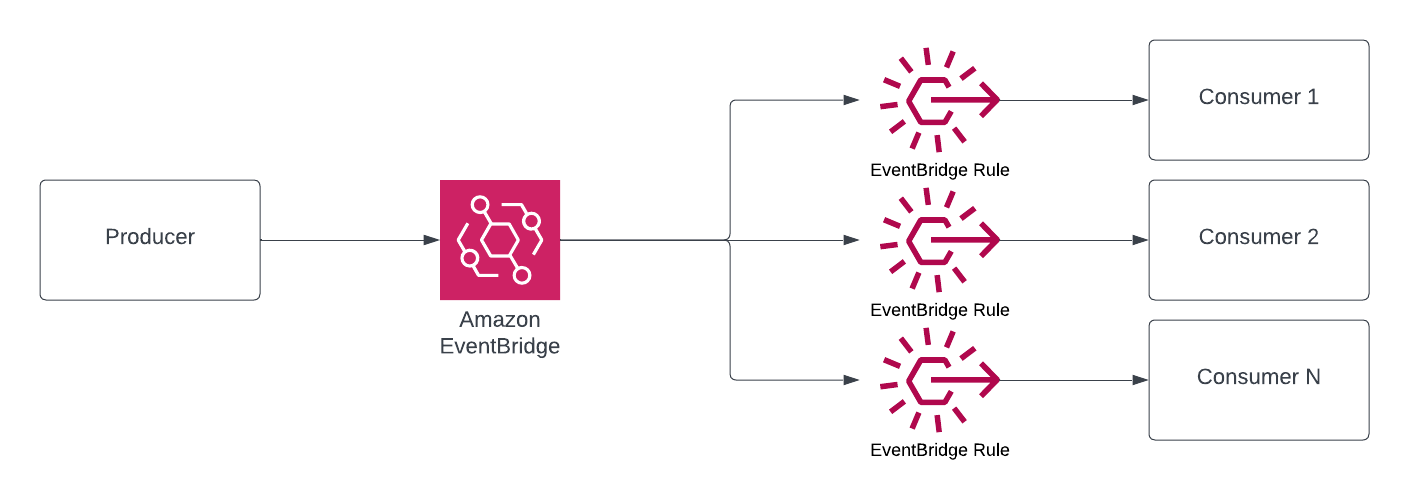
Event Summary
As you can see above, you’ve got choices in how you go about handling both producing and consuming events in a Serverless architecture. My personal feeling is that I tend to favor EventBridge as the output of my producers and I tend to have SQS sitting in front of my consumers so I can isolate delivery from consumption. Regardless of which service you take, you can rest assured that you’ll have plenty of room to scale and plenty of options to configure your preferred approach based on your needs.
Developer and Cost Experience
First and foremost for me is that unlike some other services described in my Data article, all of these services are fully supported by the AWS SDK and language of your choice. Working with the SDK is such a nice feeling as it deals with abstracting away the internal API (that makes AWS “Web Services”) in addition to handling things like retries and back-offs so you don’t have to fret too much over failure. What I want to do for each service is break down things I pay attention to when working with them in addition to the cost per transaction. Let’s get started with SQS.
SQS Dev and Cost
Working with SQS on both a producer and consumer side is super straightforward. Below is a list of what I pay attention to when using the service in no particular order.
- If you don’t want AWS Default encryption, bring your own KMS Key
- Make sure you have a Dead-Letter-Queue in the event of reading that message several times fails
- Pay attention to how long your consumer will hold the message and make that be < the visibility timeout
- Using the message delay feature can be a nice way to gain some TTL functionality out of your queues
- If not using Lambda and an SQS Event Source, make sure to delete your message after you are done processing successfully
- Make sure you need FIFO. It’ll limit your throughput
- Pay attention to polling timing. Since you are charged per call, long-polling can reduce cost and be tuned up to 20 seconds.
When it comes to pricing you get charged for how many API calls you make. This dollar amount will be different depending on if you choose FIFO or Standard and it’s tiered based on how many calls you make a month
Kinesis Dev and Cost
Working with Kinesis can be a little bit tricky and I’ve found using Lambda and a Kinesis Event Source pairs nicely to make the best developer experience. Some libraries help handle the iterator position but the most consistent experience again comes when pairing with Lambda.
- Pay attention to the trim horizon. This means how long will Kinesis hang onto the data and how far back in time you can replay those chunks of data.
- Take special care of the iterator starting position. That could either be the trim horizon (oldest data) and the last position which is when the last piece of data arrived
- Using the Lambda Event Source is the best way to consume data.
- Mind the number of consumers and what the max is and when you might want to fan out.
- Use encryption. Bring your KMS key
- Shards are your friend when you need them. And pay attention to throughput and output when scaling out via shards. This is done through message size read/write per shard.
- Poison Pill Messages are bad. Use Failure Destinations to help mitigate them
Deriving cost with Kinesis can be a little tricky. You have two options that should feel familiar if you’ve used DynamoDB before. Those modes are on-demand and provisioned. In a nutshell, you’ll pay by data you send/receive per shard and by hour of usage. There are more details underneath that statement but for this article, that’s the simple version.
SNS Dev and Cost
SNS is going to feel a great deal like the opposite half of SQS so some of the “tips” are going to feel similar. And it’s such a simple service to use (hence its name) that there aren’t too many gotchas or guidelines in there that I pay attention to.
- If you don’t want AWS Default encryption, bring your own KMS Key
- Make sure you have a Dead-Letter-Queue in the event of publishing that message several times fails
- Use subscription filters where you can. They come in either attribute or content flavors.
- Use IaC to make those subscriptions. Don’t “ClickOps” it.
For costs with SNS, they again are similar to SQS in that there is a per invocation charge but then there is also a data charge. Take note, you don’t pay to integrate SNS with Kinesis, SQS or Lambda you just pay for the data charge. And like SQS, if you do choose the FIFO option, the prices will be a touch more per category.
EventBridge Event Bus Dev and Cost
EventBridge’s Event Bus is such a cool service to work with. The buses can be constructed with CDK, SAM or native CloudFormation. They can be stitched together like I showed with Event Bus Meshes. And then the rules can be built with JSON using Event Patterns. I like the ability to push some of the boilerplate and non-differentiated heavy lifting up to the AWS platform.
I mentioned above that it includes a Pipes and Scheduler component and you should 100% take a look at those. With Pipes, you can further filter and refine/reshape/enrich messages before applying rules to them. And with Scheduler, you can trigger other services in a Cron on steroids type approach. Love both of these.
Here are a couple of articles that explore Pipes further:
- DynamoDB to Lambda via Pipes
- SNS to EventBridge Pipes — this one is a custom pattern
The things I look for specifically though when working with Buses are below:
- Pay attention to the standard message structure. It’ll make sense after a while. And embrace expanding it for your needs
- Filters with Event Patterns are powerful. Learn the syntax
- You might be able to get away with one Bus, but if you are following Domain-Driven Design, the Bus Mesh makes a lot of sense.
- Use IaC to build rules. Trust me on this.
- Look into the Schema Registry. I admit I haven’t used as much as I should but if I was starting my current project over and this existed, I’d be making use of it.
- You can connect existing AWS service events via Buses. Think CloudTrail. So much that can be done with the native services.
When it comes to price, the great thing about EB Buses is the simple pricing model. You pay per request and size. 64Kb chunks are 1 request. If your message is > than 64Kb it’s just another request charge. And when you look at integrating other services in the AWS ecosystem, it’s free of charge!
Wrapping Up
This is probably the meatiest of all of the Summer Serverless Series because at the heart of an EDA and Serverless design is this notion of decoupling your features via asynchronous event processing. So that squarely puts “events” and the services that are in the business of storing and routing those events right in the middle of the architecture.
When looking at these services, you can’t go wrong with a simple SNS-SQS implementation but I’d implore you to look a bit deeper at EventBridge and its Buses. I’m such a huge fan of that service that I wouldn’t be doing my job as a Serverless writer if I didn’t share that opinion. The second thing that I think you need to do is establish a common message structure. The structural format and the verified content of that payload and its need to be consistent and is of vital importance.
The last piece of guidance I will live you with is this. Many others have stated it but I want to reiterate this fact. Event-Driven and Serverless systems are going to look more complex on the surface than something that is more co-located and coupled. And on the surface, I’m not going to sugarcoat it that it will look that way. There is complexity, but the flexibility that you gain from having small and decoupled components will outweigh the newly added responsibility of handling idempotency, eventual consistency and data replication. I’ve been running this style of architecture with AWS for the past 8 years and while it’s not perfect, it’s super powerful and fun to build upon.
Until the next in the series … Happy Building!


