

Building Serverless applications can feel a bit overwhelming when you are first getting started. Sure, Event-Driven Systems have been around for many years but this notion of using managed services to “assemble” solutions vs a more traditional “plugin” style architecture might throw you for a loop. Continuing in the series of Building Serverless Applications with AWS, let’s have a look at the “Compute” aspect.
Series Topics
- Data Storage Choices
- Building the Application (Fargate/Containers vs Lambda)
- Handling Events
- Exposing the API (if there is one)
- Securing it all, including the API
- Debugging and Troubleshooting in Production
Building Serverless Applications – Compute
One could make the argument that compute portion of the Serverless stack might be the most important. I’m not sure that I agree with that, however, it is a critical component as it’s where your code runs. I mostly believe that your app is going to have code running somewhere, regardless of whether it’s Serverless or “Serverfull” and that all of the supporting services are really what makes this paradigm shine. Moving on from the pontification, I see compute being divided into two different runtimes when I’m architecting Serverless solutions. Those two are AWS Fargate and AWS Lambda.
I’d first like to define what category of compute these two are in my mind and then start to break apart the differences and the nuance of putting them into your build.
AWS Fargate
AWS Fargate is a serverless, pay-as-you-go compute engine that lets you focus on building applications without managing servers. AWS Fargate is compatible with both Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Service (EKS). – AWS.
AWS
And to further illustrate, here is their infographic
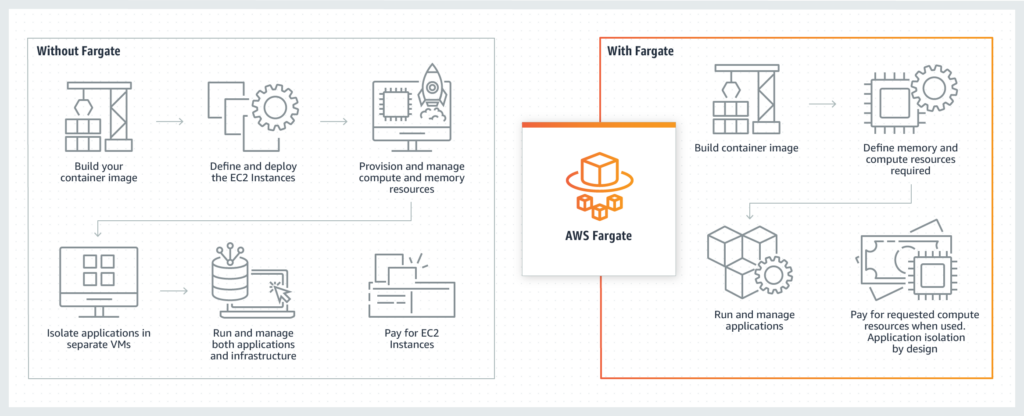
Think about it this way. You build a container image (Docker) and then based on that image’s memory and CPU requirements, you ask Fargate to create a Task with those given parameters.
AWS Lambda
Compare that with AWS Lambda which is described by AWS like this.
AWS Lambda is a serverless, event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. You can trigger Lambda from over 200 AWS services and software as a service (SaaS) applications, and only pay for what you use.
AWS
The way I think about when to use Lambdas is largely by what is going to trigger them and if the demand is consistent or possibly bursty. What I mean by this is that if I have a constant demand, I might reach for Fargate because I can scale predictably. But this is really only a “might” and generally boils down to who is doing the building and the supporting. I’ll explain more as I get into the article.
The Compute Criteria
So if we want to look first at perhaps some “hard” criteria to understand one vs the other, these are the questions that I might ask.
- Does your code run in bursts or perhaps not consistently throughout the day?
- Does the idea of only paying for resources used to appeal to you?
- Are you connecting to other Serverless services and using those things as Event Triggers?
- Do you have a lot of passion for containers or prefer to just write your code and let AWS take care of the rest? (Side note, sure you can deploy custom images into the Lambda runtime but controversially I say why?)
If you answered yes to those questions and maybe no to the last, I would tend to think that you are going to be looking to deploy in Lambda. But let’s look at the converse of that why you might look at Fargate.
- Are you bringing legacy code to the cloud that’s currently already running on-prem or maybe even in EC2?
- Is your workload more consistent and even balanced? Can you perhaps shut things off after hours or will you have steady demand after hours?
- Is your scaling predictable or are you comfortable scaling up to meet demand with alarms and triggers to provision new infrastructure?
- Do you have a longer running task that instead of using Step Functions you’d feel better running in a host? Lambda will drop you at 15 minutes so this might matter.
Answering yes to the above lends me to thinking about Fargate. If you are looking for building consistent workloads with more Opensource and non-AWS frameworks, then go with Fargate. It’s going to give you that EC2 but still Serverless feel.
Compute Summary
The real truth here is that you can make some awesome and valuable applications with either of these services. I tend to use Lambda over Fargate, but that’s due more to the way I like to code and ship than Lambda being any better than Fargate. I know other peers that like Containers so much more than Functions and they choose Fargate all day. It’s a matter of what fits what you are trying to accomplish.
So for the balance of this article, I want to address how to operate these two services to better give you a view of how to choose between them.

Working with these Compute Services
What does this mean though for you as a developer or architect? Again, let me state that you can have success with either of these services in all the same use cases. So unless you’ve got something like the > 15 minutes greater than rule or you have a really large binary, you can run both of these just fine.
I’m going to break each of these down into the following categories:
- Deploying your code
- Configuring common parameters
- Cost
- Overall Developer experience / Gotchas
Please remember, these are my takes from my experiences. It’s not exhaustive and I’ll never profess to be an expert at anything and especially something that is so open-ended as Serverless. But in the end, as a new developer to Serverless, I hope you find them helpful.
Deploying your Code
I’m going to start with Lambda and then pivot into Fargate as I work through these elements.
For a Lambda, you have two approaches for getting your code to where it can be executed. Path A is to create a container image where you can use SAM or using the Docker CLI to build your image from one of the AWS bases. Path B is to create a Lambda Deployment from a zip file that is an archive of sorts. Each archive might look a little different depending upon your language of choice. There is a list of support runtimes including custom ones that you can leverage.
Whichever path you follow, A or B, the code needs to be ready to handle the event that you are going to be receiving. What makes Lambda very different from running Fargate is that the entry point to your function is going to be a handler with a specific event payload it expects. Root level, it could be JSON, or it could be something strongly typed. Again, it really will depend upon your language. This is a stark contrast to what you’ll see in Fargate below.
With Fargate things are a little more “standard” from a non-Serverless perspective. You need a container image that will execute your code. This code can then be whatever you wish. For instance, let’s say you have a Java Spring Boot web server or a Golang Gin web server. You’ll need a main and then that code will fire off your web server. It’s going to feel just like if you were running in EC2 or on your laptop. What I like about Fargate, is that if you are coming from a more traditional background, getting into Serverless is much more straightforward. This is especially true if you are coming from previous Docker experience. I’ve seen many developers start here before they ever deploy their first Lambda function.
Configuring Common Parameters
Understanding how your Serverless service works and how it can be tuned can be one of the biggest things that take time and experimentation. As a developer, it’s as important as learning the API of any other dependency in your stack, but sometimes learning it takes running it. Hopefully, the below will help you gain some insight into the things that will initially matter.
There is a great deal more than what I’m about to share, but for starters, these are the things that are most important in my eyes when one’s learning these compute platforms.
Lambda Parameters
For Lambda, the things that matter the most to me are this and in no order of importance.
- Memory allocated: This tells Lambda how much memory is assigned to your function and also proportionately assigns vCPU. There’s no setting for CPU but you’ll see there will be a sweet spot for how much memory balances against performance
- Environment variables: Seems simple right? But having the right variables configured makes your Lambda more adaptable so that you can alter behavior without changing code.
- VPC Settings: I’m going to be honest, I rarely ever use this. But when you need to use something inside your VPC, you’ll need to specify the VPC and the Subnets that you want your Lambda attached to.
- IAM Policies: Your Lambda will get its permissions from the policies that are attached to it. When you look at using the SDK for calling any other services, you won’t need an ACCESS_KEY_ID or SECRET_ACCESS_KEY as the SDK will pick those up from your Lambda when it runs. So pay attention to what you grant in there and only grant what you need.
- Concurrency: By default your account will only allow so many Lambda invocations at one time. Additionally, you might need to restrict the number of versions of this code running at any one time. Setting the max concurrency on your Lambda can be important.
- Last and it’s a big last. Learn the configurations for the Events that will trigger your Lambda. For SQS, how many messages per poll. For Kinesis, what’s the batch size and what happens on failures? So many things to learn here.
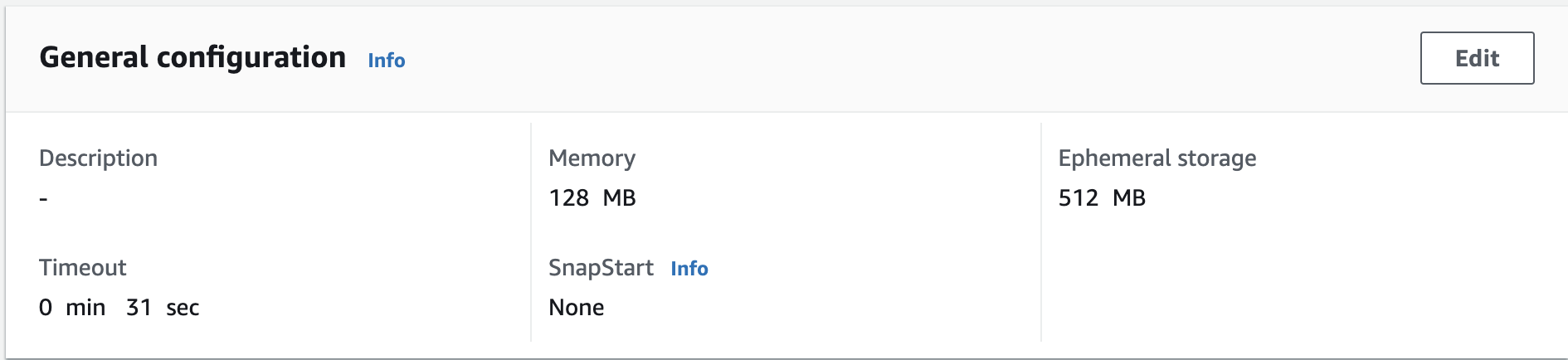
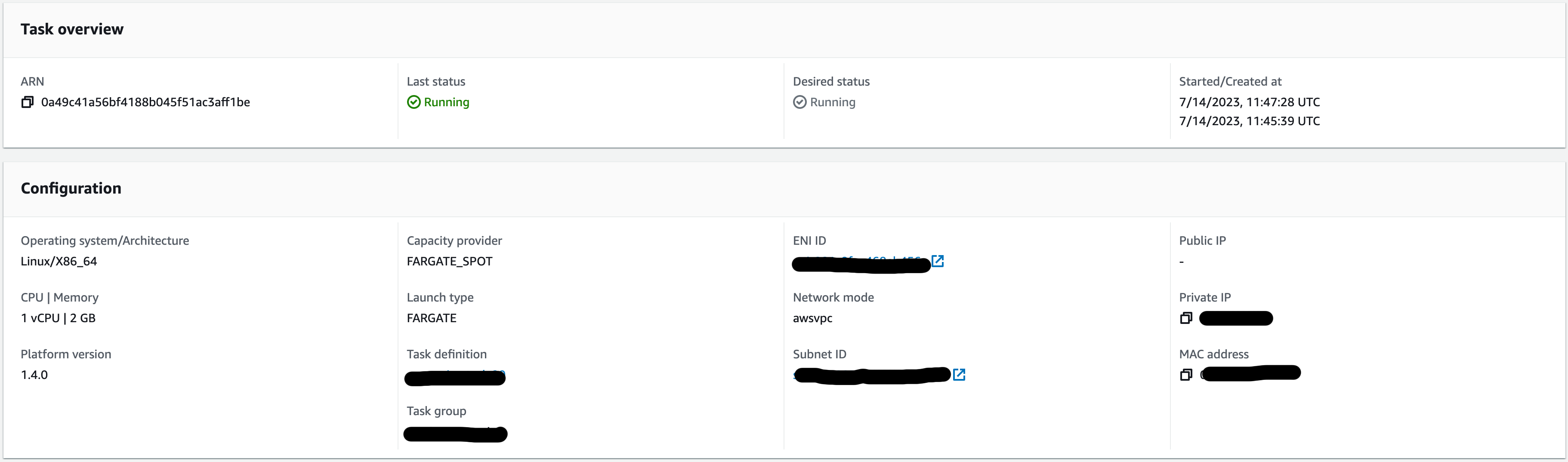
Fargate Parameters
When working with Fargate, I can’t write up anything much better than what’s already done in the AWS documentation.
But what I will do is point out what I think is important when you start. So those key things are this.
- vCPU: This means just what you think it does. How much/many CPUs do you want to allocate to your container
- Memory: Also super straightforward. You need to balance vCPU with Memory as there are combinations that you can’t create. But in general, you should find this to be what you expect.
- IAM Policies: Your Fargate Task will get its permissions from the policies that are attached to it. When you look at using the SDK for calling any other services, you won’t need an ACCESS_KEY_ID or SECRET_ACCESS_KEY as the SDK will pick those up from your Task when it runs. So pay attention to what you grant in there and only grant what you need.
- Docker Settings
- Which ports are you opening and which port is the internal one listening to? They might be different
- What’s the HealthCheck (endpoint)
Compute Cost
Now here’s where there is a good bit of difference and something worth thinking about.
Lambda Cost
For Lambda first, here is what AWS says.
Lambda counts a request each time it starts executing in response to an event notification trigger, such as from Amazon Simple Notification Service (SNS) or Amazon EventBridge, or an invoke call, such as from Amazon API Gateway, or via the AWS SDK, including test invokes from the AWS Console. Duration is calculated from the time your code begins executing until it returns or otherwise terminates, rounded up to the nearest 1 ms*. The price depends on the amount of memory you allocate to your function. In the AWS Lambda resource model, you choose the amount of memory you want for your function, and are allocated proportional CPU power and other resources. An increase in memory size triggers an equivalent increase in CPU available to your function
AWS
What the above means is that you are charged for the size and duration of your function where size is measured in Memory Allocated. Take for instance a simple Queue event handler that only runs a handful of times a day. It really makes very little sense to have a container in Fargate running for something like this. Of course, you could spin it up, spin it down and whatnot, but why take that overhead? Additionally, you might have a Lambda that runs a million times a day. I could make the argument that the Fargate task would be cheaper if the request overhead makes sense, but then ask, what if the container doesn’t need to be up overnight? It might be a mix of Fargate and then turning it off? Or perhaps even further, you don’t want to worry about it and you are willing to pay the overhead to run Lambda all the time. That’s your choice as well.
With anything, unless you are racking your equipment, perfectly sizing and going bare metal, one can always argue “cost”. I wrote about what I think is the true cost of Serverless so might be worth taking a read.
Fargate Cost
Per AWS, here’s how Fargate pricing works.
AWS Fargate pricing is calculated based on the vCPU, memory, Operating Systems, CPU Architecture, and storage1 resources used from the time you start to download your container image until the Amazon ECS Task or Amazon EKS2 Pod terminates, rounded up to the nearest second.
AWS
Pricing is based on requested vCPU, memory, Operating Systems, CPU Architecture, and storage1 resources for the Task or Pod. The five dimensions are independently configurable.
AWS
Bottom line, you are going to get charged for the architecture, storage, compute and memory that you need. From there, it’s easy. You don’t need to worry about where the container is deployed or even how just that you have an IP address that is in front of your container that is running your code and exposing the ports you’ve asked for with the parameter settings you specified.
You then pay for what you use while it’s running. Not events. Just time running. You could handle millions of events an hour with a static price by the number of nodes times the chargeable parameters. Additionally, you could pay that same price if you do no traffic over that same period.
It’s for that reason that even though it’s Serverless, you are paying for time running and not events handled. So use that to your advantage.
Overall Developer experience / Gotchas
OK, so this is super subjective so I’m not going to talk about which one is better than the other. I’m already on the record that I love Lambdas and tend to use them more. But when I’ve got very consistent workloads and want maybe a little more control over my frameworks, I go Fargate. The nice thing about Fargate too is that you can leverage ECS or EKS as the container management platform from AWS. I won’t begin to step into that battle, but for me and probably you unless you are a Kubernetes ninja, is to just start with ECS.
Lambda Experiences
The things that I think you need to be careful about are as follows when it comes to Lambda.
- Pay attention to where your logs are going. You are going to need to debug and logs matter. Use a JSON formatter where possible.
- Watch exceptions, throttles and concurrency. Remember, you are looking event over event. Very much like a “request”. Those metrics are going to matter as you get better at using Lambda. Seriously, learn to watch these like a hawk.
- Downstream needs and concurrency. Again with the concurrency. I’ve seen Lambdas flood downstream resources because AWS will keep spinning up more Lambda nodes regardless of what other systems require. If you have a pool of DB connections, and your DB can deal with 100 connections, but each of your Lambdas opens 10 connections. Guess what, 11 Lambda invocations will render your DB useless. WATCH THIS
- If you’ve got shared code, look at Layers or Extensions. These are powerful and I think under-used.
- Function timeout. How long will your code be allowed to execute? You have a max of 15 minutes, but let’s say you forget to deal with failure. If so, your Lambda will hang on for the timeout you set thus racking of the bill for code that’s wasted.
- Embrace testing in the cloud. I know I love local development, but I’m slowly coming around. It’ll make your life easier.
Fargate Experiences
My opinions of working with Fargate are so positive and straightforward that my things to learn from are pretty simple.
- If your container doesn’t need to be up, shut it down. It’ll save you cost.
- If you need more capacity, burst sooner. Your service might take 60 – 120 seconds to become healthy. You’d hate to have users experience that unavailable moment because you scaled too late.
- You might not need as much memory and CPU as you think. Play with this.
- Make your HealthCheck robust. This is just good container management but I felt I needed to say it.
- You are going to get charged to pull your image. So invest in small images 🙂
- I cannot say this enough. If you are looking to migrate to Serverless, taking Spring Boot, ASP.NET Core, a Golang web server and putting in Fargate is easy. Especially considering that you might already have the image defined. Then it’s even that much easier.
Pretty simple list honestly. I love Fargate. I don’t use it nearly as much as I think I should, but it’s a fantastic service and something you need to be using.
Wrapping Up
Alright, so that was 3000 + words on Compute. I didn’t intend to do that much, but as you can see from the above (if you are still with me), there’s a lot to process. Pun intended.
This to me is one of those things where you really can’t go wrong. AWS has done an amazing job giving Serverless developers and architects two world-class compute platforms.
If you want per invocation control, out-of-the-box events, pay as you go pricing, then Lambda is your choice. If you want a more familiar Docker experience with higher-level control than what you’d have with fine-grained EC2, then Fargate is your huckleberry.
I also think that you will mix and match these as you see fit and as you learn more and run more. When building in Serverless, things are often small so you aren’t locked in. Be my guest to experiment and see what works best for your environment.
Most of my guidance above comes from 100s of millions of executions on both platforms and learning about how they operate and how I can bring the best value to my end users. I sincerely hope that you’ve gained some knowledge that’ll help you do the same thing.
Until the next in the series … Happy Building!


