Amid everything going on, I stayed up after Day 2 of re:Invent to get my hands on the new Amazon S Q Digital Assistant. For more on the release here is the announcement. While sitting in the Adam Selipsky Keynote yesterday, a use case instantly popped into my head. The below example has no CDK or SAM but is purely a simple walkthrough of the functionality. Let me tell you about a time that Amazon Q met Taylor Swift.
I’ve been working recently with some data that doesn’t naturally fit into my AWS HealthLake datastore. I have some additional information captured in a DynamoDB table that would be useful to blend with HealthLake but on its own is not an FHIR resource. I pondered on this for a while and came up with the idea of piping DynamoDB stream changes to S3 so that I could then pick up with AWS Glue. In this article, I want to show you an approach to building a partitioned S3 bucket from DynamoDB. Refining that further with Glue jobs, tables and crawlers will come later.
When working on building solutions, the answer to some problems is often, it depends. For instance, if I need to deal with data as it changes and use DynamoDB, streams are the perfect feature to take advantage of. However, some data doesn’t need to be dealt with in real-time, once a day or every 30 minutes might be good enough. This was problematic up until recently, as AWS released incremental exports with DynamoDB. In this article, I want to explore building an incremental export with DynamoDB and Step Functions.
I’ve been wanting to spend more time lately talking about AWS HealthLake. And then more specifically, Fast Healthcare Interoperable Resources (FHIR) which is the foundation for interoperability in healthcare information systems. I believe very strongly that Serverless is for more than just client and user-driven workflows. I wrote extensively about it here but I wanted to take a deeper dive into building out streams of dataflows. I’ve been using this pattern for quite some time in production, so let’s have a look at EventBridge Pipes enriching DynamoDB Streams.
In my previous article I wrote about a Callback Pattern with AWS Step Functions built upon the backbone of HealthLake’s export. As much as I went deep with code on the Callback portion, I felt that I didn’t give the HealthLake side of the equation enough run. So this article is that adjustment. Managing exports with AWS HealthLake.
What is HealthLake
AWS HealthLake is a HIPAA-eligible service that provides FHIR APIs that help healthcare and life sciences companies securely store, transform, transact, and analyze health data in minutes to give a chronological view at the patient and population-level. – AWS
My words on that are that HealthLake is a FHIR-compliant database that gives a developer a robust set of APIs to build patient-centered applications. You can use HealthLake for building transactional applications, analyze large volumes of data, store structured and semi-structured information and build analytics and reports.
When building with HealthLake I find it fits in one of two places.
As the transactional center for your Healthcare application. It is highly patient centered, very scalable and contains APIs for working with each resource. In addition, it provides SMART on FHIR capabilities that make it nice choice for building an application on top of.
As the aggregation point for many external and internal systems in a LakeHouse style architecture for interopability and reporting. When you’ve got a distributed system with various datababases and you need your data reunited in one location. HealthLake does that. Or if you are pulling in data from various external sources, HealthLake can do that too. I wrote about doing this with Serverless a while back.
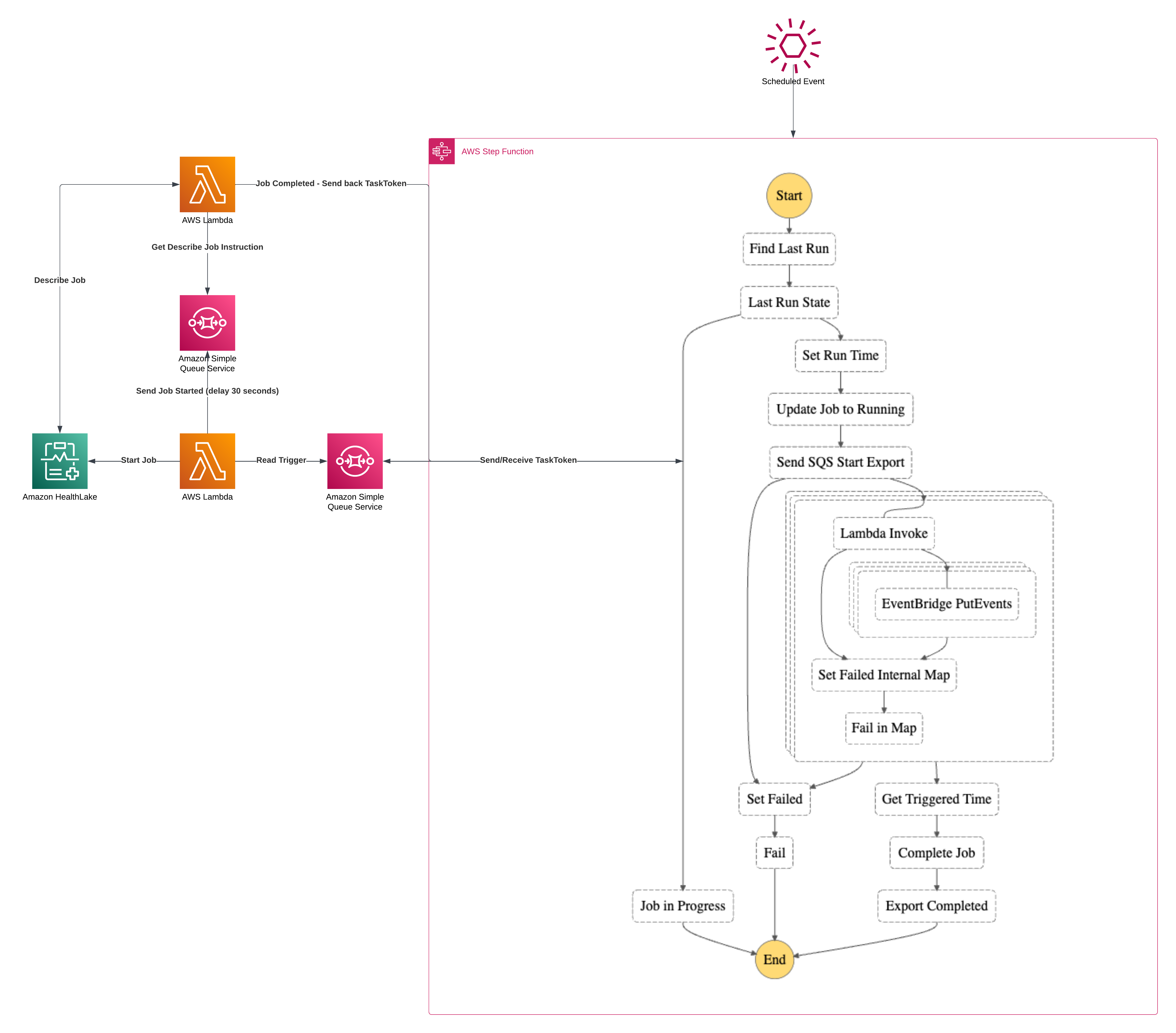
Some operations in a system function asynchronously. Many times, those same operations must also happen to be responsible for coordinating external workflows to provide an overall status on the execution of the main workflow. A natural fit for this problem with AWS is to use Step Functions and make use of the Callback pattern. In this article, I’m going to walk through an example of the Callback pattern while using AWS’ HealthLake and its export capabilities as the backbone for the async job. Welcome to the AWS Step Functions Callback Pattern.
Callback Workflow Solution Architecture
Let’s first start with the overarching architecture diagram. The general premise of the solution is that AWS’ HealthLake allows the export of all resources “since the last time”. By using Step Functions, Lambdas, SQS, DynamoDB, S3, Distributed Maps and EventBridge I’m going to build the ultimate Serverless Callback workflow. I feel like outside of Kinesis and SNS, I’ve touched them all in this one.
There’s quite a bit going on in here so I’m going to break it down into segments which will be:
Triggering the State Machine
Record Keeping and Run Status
Running the Export and initiating the Callback
Polling the Export and Restarting the State Machine
Working the results
Wrapping Up
Dealing with Failure
Hang tight, there’s going to be a bunch of code and lots of detail. If you want to jump to code, it’s down at the bottom here
Building Serverless applications can feel a bit overwhelming when you are first getting started. Sure, Event-Driven Systems have been around for many years but this notion of using managed services to “assemble” solutions vs a more traditional “plugin” style architecture might throw you for a loop. I haven’t created a series yet, so this is my first attempt at that. My goal is to walk you through the design considerations when Building Serverless Applications with AWS.
Building the Application (Fargate/Containers vs Lambda)
Handling Events
Exposing the API (if there is one)
Securing it all, including the API
Debugging and Troubleshooting in Production
This is an ambitious list, but when I think about what it takes to put together a Serverless application, these are the concepts and decisions that I often end up counseling or guiding developers new to the paradigm. So let’s dig in.
Follow me along on a journey toward data unification. One of the applications that I work on is a modern, distributed, event-driven and serverless-based architecture. What that means is that data is completely isolated from other components and evolves at a different pace from its neighbor. This type of architecture is achievable using Event-Driven Serverless Data Architecture with AWS.
This is great if you are building a transactional system. You’ve got isolation, independent component scaling and feature delivery that goes at the pace of the team working on it. So what could be wrong? What possibly isn’t good about this outside of the fact that modern distributed systems are complex? The big issue is that all of this data is not in the same place.
What’s the point in having everything in the same place you ask? Simple. Source of truth for:
Reporting
Public APIs
Versioning
Audits
Data Sandbox
These are just the tip of the iceberg. When you are working on a big system with lots of data, having a single ingress and egress point is important when you are talking about the above.
I know it’s 2023, but you can’t get away from processing files. In a world of Events, APIs and Sockets, files still exist as a medium for moving data around. And a very common one at that. In recent years I’ve found myself dealing with Apache Parquet format files. And more specifically I often end up dealing with them coming out of AWS S3. If you are a consumer at all of the AWS DMS product when replicating, you will find out that parquet format is a great way to deal with your data as its designed for efficient storage and retrieval. There aren’t too many options for parsing a parquet file with Golang, but I’ve find a library I really enjoy and the article below will describe how to make the best use of it.
As always, here is the link to the Github Repository if you want to skip ahead
Short post on unmarshalling a DynamoDB Map into something strongly typed like a Go struct. If you want to jump straight to some code, here are the Github gists