

I’ve been wanting to spend more time lately talking about AWS HealthLake. And then more specifically, Fast Healthcare Interoperable Resources (FHIR) which is the foundation for interoperability in healthcare information systems. I believe very strongly that Serverless is for more than just client and user-driven workflows. I wrote extensively about it here but I wanted to take a deeper dive into building out streams of dataflows. I’ve been using this pattern for quite some time in production, so let’s have a look at EventBridge Pipes enriching DynamoDB Streams.
Setting up the Problem
I’ve previously written about EventBridge, Pipes and DynamoDB but I wanted to take a little more of a closer look at how to enrich those stream changes. Using FHIR as a backdrop seems like a perfect way to go.
When working with FHIR, there are certain specifics for each resource that need to be on the record. One could argue, why not just store your data model for your transactional system in FHIR? I’ve tried that before. It’s rough. As changes come through, you might be making transactional-level adjustments to your schema that break your domain boundaries. FHIR is an extensible specification that fits a lot of healthcare scenarios. It’s a large blanket of a specification that I find is better applied to translate into and out of vs. storing natively in that format.
With that decision consideration in place, I need to be able to transform my domain-specific data models into FHIR. Sometimes, I might need to do lightweight translations to get from JSON or relational into FHIR. And sometimes I might need to enrich the changed record with additional information as again, FHIR might not line up 1:1 with my models.
One of my favorite things about using DynamoDB is streams. It is such a powerful concept that makes triggering a change in your system so achievable. That change in this example is going to be in make-believe but could be a real Patients table. Those changes will be streamed from DynamoDB then processed by EventBridge’s Pipes and then Filtered, Enriched and then written into CloudWatch. They could be written to Kinesis or HealthLake or an API destination, but I wanted to focus on the enrichment and filtering for now.
The Workflow
As with most of my articles, fully working code will be at the bottom. I’ll plan to sprinkle some in this writing but you can expect CDK (TypeScript) and Golang.
DynamoDB Patient
For the Patients table, I’ve got a simple setup.
this._table = new Table(this, id, {
billingMode: BillingMode.PAY_PER_REQUEST,
removalPolicy: RemovalPolicy.DESTROY,
partitionKey: { name: "id", type: AttributeType.STRING },
tableName: `Patients`,
encryption: TableEncryption.CUSTOMER_MANAGED,
encryptionKey: props.key,
stream: StreamViewType.NEW_AND_OLD_IMAGES,
});
This is some CDK code that builds a Patients table. This table will be encrypted by a custom KMS Key and will propagate New and Old Image Changes via Streams. When the table is deployed via the CDK Stack, you’ll see the new table with stream changes “On”.

I’ve got the basics set up now that when I want to enrich this DynamoDB Stream with EventBridge Pipes, I’m ready to go.
To create a FHIR Patient Resource, I need to be able to convert my domain Patient into that FHIR resource. That initial Patient is stored in DynamoDB with a mixture of Strings and a Map which defines the address field.
The base Patient record I’ll be working with to transform looks like the below:

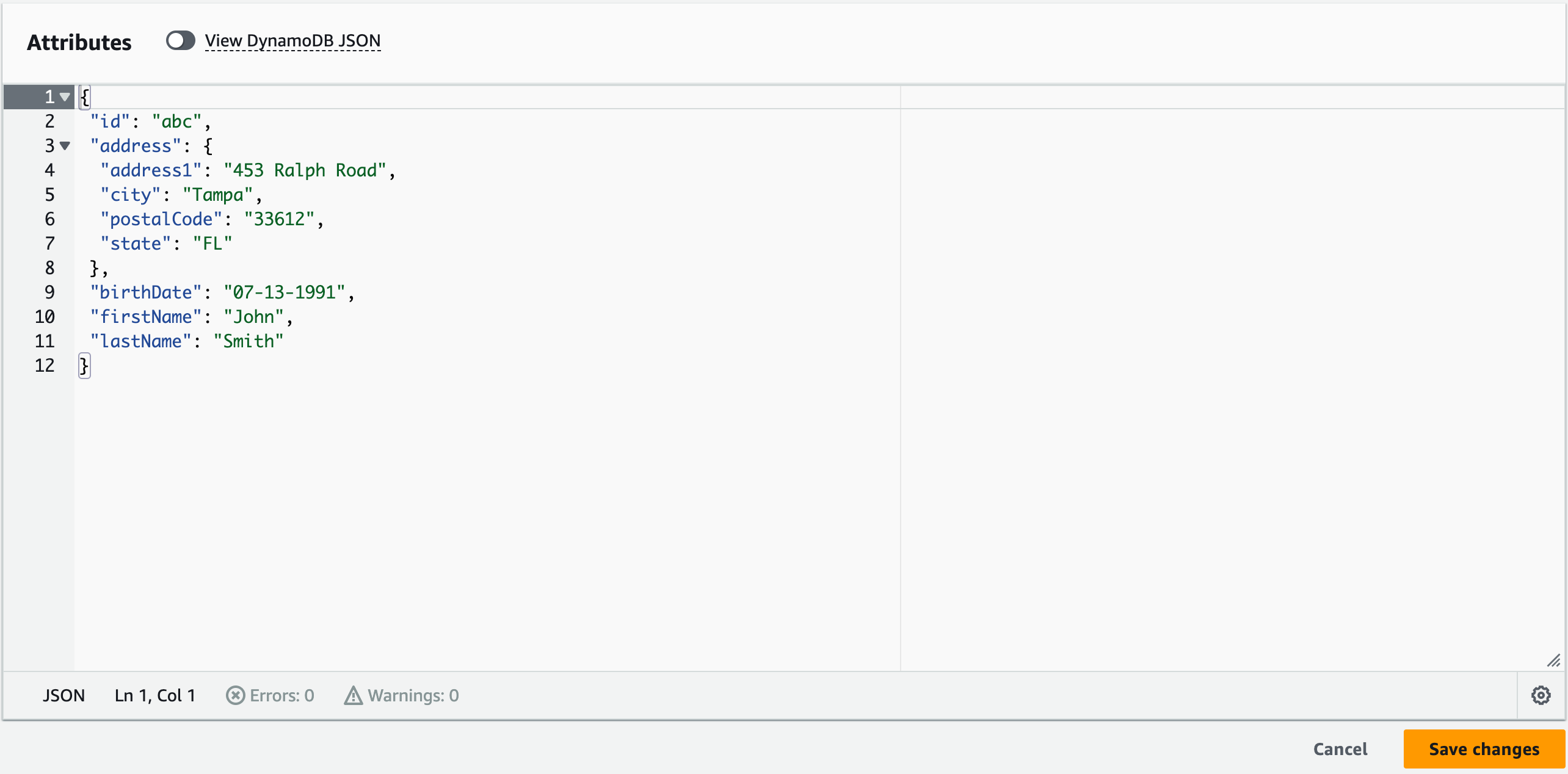
When anything happens to that record, it will be streamed out for me to do something to do with.
EventBridge Pipes
Handling DyanmoDB streams with EventBridge Pipes is the epitome of a Serverless workflow. DynamoDB is serverless, Pipes are Serverless and my filtering, transformation and enrichment are all powered as Serverless. The Pipe looks like this.

The CDK code that builds the pipe is kind of interesting to put together. There is some decent documentation on the CDK site, but I did have to reference a couple of different locations to pull together the final.
const pipe = new CfnPipe(scope, "Pipe", {
name: "Patient-StreamChange-Pipe",
roleArn: pipeRole.roleArn,
// eslint-disable-next-line @typescript-eslint/no-non-null-assertion
source: props.table.tableStreamArn!,
enrichment: props.enrichmentFunction.functionArn,
target: logGroup.logGroupArn,
sourceParameters: this.sourceParameters(),
targetParameters: this.targetParameters(logGroup),
enrichmentParameters: this.enrichmentParameters(),
});
That’s the general pipe build. A good bit is going on in building each of the parts of the flow. I won’t dump the entire file here, but what I find interesting I’ll highlight.
sourceParameters = () => {
return {
dynamoDbStreamParameters: {
startingPosition: "LATEST",
batchSize: 1,
},
filterCriteria: {
filters: [
{
pattern: ' { "eventName": [ "MODIFY", "INSERT" ] }',
},
],
},
};
};
For source, I’m connecting EventBridge Pipes to DynamoDB Streams via Stream Parameters. Additionally, I’m only processing in this pipe those changes that are Modifications and Insertions. Adding a filter is amazing and while reading from streams, it’ll just advance the iterator forward when records don’t match.
The other part that needs some focus is the enrichment step. For my enrichment in this example, I’m not shaping the payload. The reason for this is that when working with Golang, there is a struct that matches the exact format of the stream record. However, if you had some other record coming in, transforming with the inputTemplate is the way to go.
enrichmentParameters = () => {
return {
lambdaParameters: {
invocationType: "REQUEST_RESPONSE",
},
inputTemplate: ``,
};
};
Enriching the Stream
I love how EventBridge Pipes gives me the ability to enrich the payload along the way. You’ve got options in the enrichment phase, but I’m going all Serverless here so a Lambda fits just nicely.
Setting up the operations, I want to convert the data from the DynamoDB Patients table record into something that is FHIR compliant. As of now, my preferred Lambda deployment is using the Amazon Linux v2 runtime with a Golang binary.
My Golang handler is super simple and I’m going to show it right below. But as I mentioned above, having a DynamoDB Stream record, it’s easy to marshal it into a DynamoDBEventRecord struct. Notice that it’s an array that is coming in. I’m expecting 1 record by the batch size that I set in my processing in the CDK code.
func handler(ctx context.Context, e []events.DynamoDBEventRecord) (*PatientEvent, error) {
log.WithFields(log.Fields{
"body": e,
}).Debug("Printing out the body")
if len(e) != 1 {
return nil, fmt.Errorf("wrong number of entries supplied")
}
fhirPatient, err := buildPatientEvent(&e[0])
if err != nil {
log.WithFields(log.Fields{
"err": err,
}).Error("Something bad happened when building the Patient Payload")
return nil, err
}
log.WithFields(log.Fields{
"fhirPatient": fhirPatient,
}).Debug("Printing out the payload")
return fhirPatient, nil
}
I am returning a PatientEvent for further processing in the stream. That PatientEvent looks like a combination of FHIR plus some metadata.
type PatientEvent struct {
Version string `json:"version"`
Source string `json:"source"`
EventType string `json:"eventType"`
CorrelationId string `json:"correlationId"`
Details struct {
Command string `json:"command"`
Body fhir.Patient `json:"entity"`
} `json:"details"`
}
I like to include more information in my pipeline processing so that I can use that extra data down the line. The main FHIR Patient is stored in the Body field.
I then delegate the conversation to that `Body“ element in a function that operates on the stream.
func buildPatientEvent(r *events.DynamoDBEventRecord) (*PatientEvent, error) {
pe := &PatientEvent{
Version: "1.0",
Source: "PatientTable",
EventType: "PatientChange",
CorrelationId: r.EventID,
Details: struct {
Command string `json:"command"`
Body fhir.Patient `json:"entity"`
}{
Command: "PUT",
},
}
fhirPatient := fhir.Patient{}
// more code in the repos
return pe, nil
}
What I like about doing things this way is that the conversion code for each resource is isolated to the single enrichment function that does that conversion. Should an FHIR resource change its definition for some reason, I only need to make these adjustments in one place. And if I’ve got good unit tests and coverage around this code, then even better. I find that the single responsibility principle comes into play big time here.
The Target
When enriching DyanmoDB Streams with EventBridge Pipes, I’ve got a lot of options in terms of targets. I could put the enriched payload on a Queue, start a State Machine, or use an API Destination, but in this case, I’m just going to dump it out to CloudWatch.
targetParameters = (logGroup: LogGroup) => {
return {
cloudWatchLogsParameters: {
logStreamName: logGroup.logGroupName,
},
};
};
The target of CloudWatch just requires a LogGroup that I want to send the output towards.
If I look at the Lambda output, the details are available in CloudWatch.
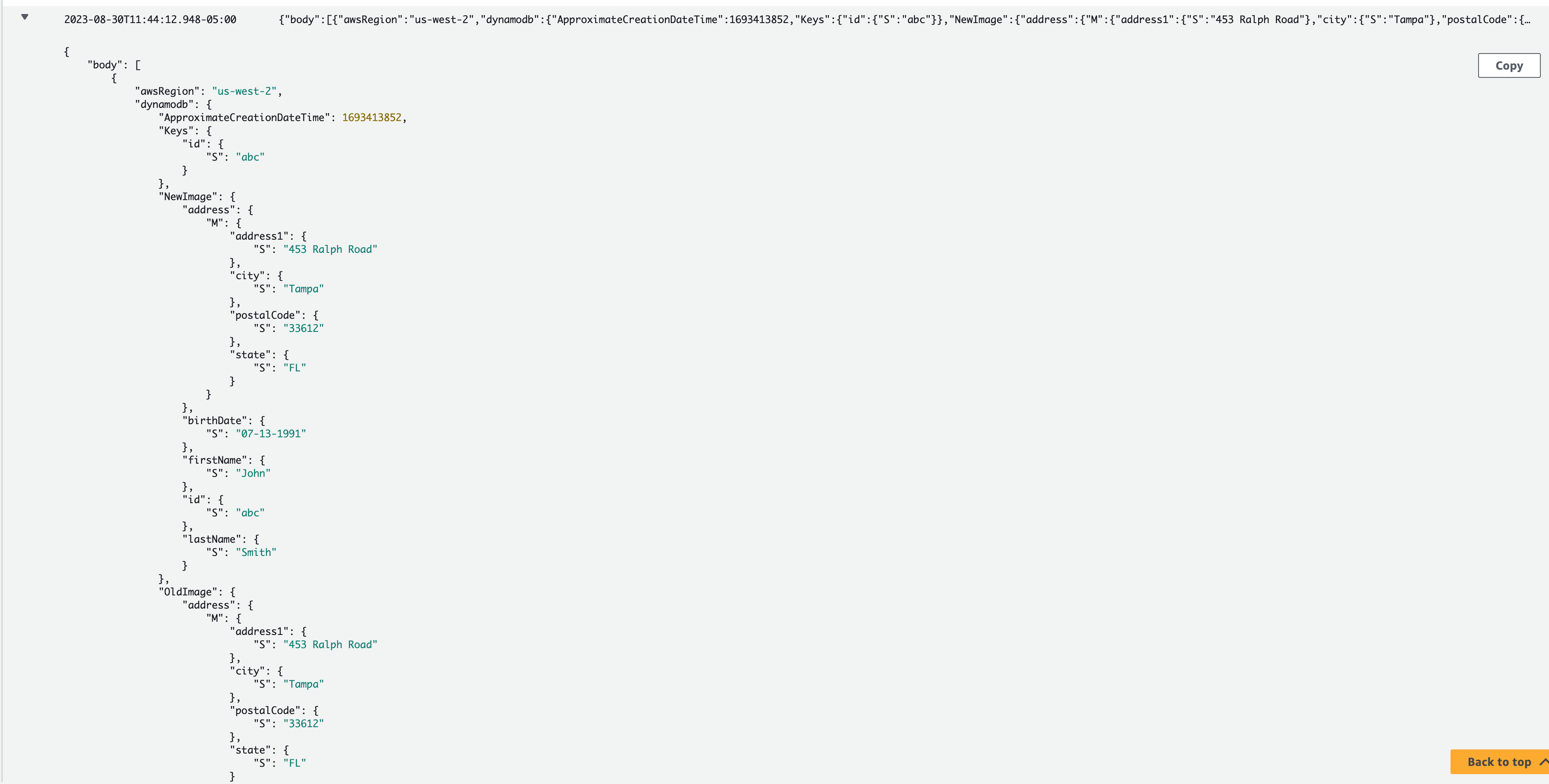
But then if I look at the output coming from the Enrichment step in the Pipe, that output is simply what I’m returning from the Lambda function. Remember the PatientEvent? That’s what will appear in the CloudWatch stream.
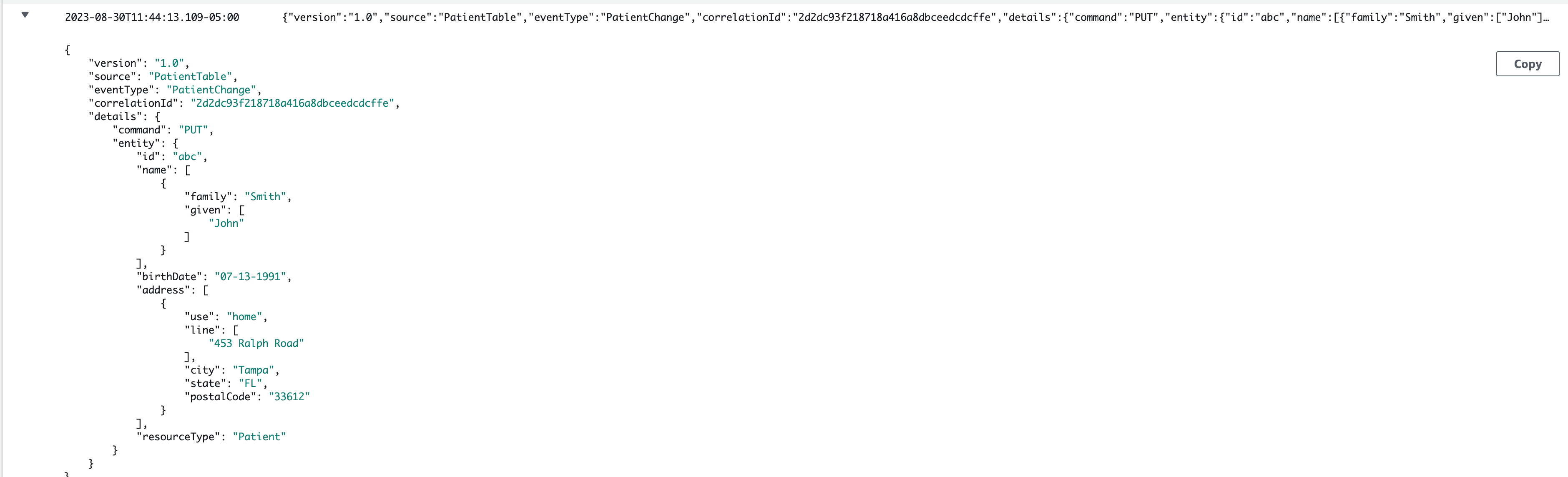
Easy peasy. A domain-specific Patient has now been converted into an FHIR Patient Resource for use in something like HealthLake or any other processing.
Wrapping Up
The HL7 FHIR specification is a super powerful way to define healthcare resources so that they are interoperable amongst other healthcare systems. It can be a lot to process and digest when you are getting started but by using something that is standards-compliant like HealthLake, you should have a nice start on your journey.
I mentioned earlier that there would be sample code. You can find everything that works in this article in the following repository. Follow the README to get set up and ready to play around.
My last couple of articles have been around HealthLake, FHIR and Healthcare because I feel strongly that there are still too many unspoken questions in this domain. Things like picking the right language, the right tech, or the right standards just don’t seem to come up enough. I hope to change that by just sharing what’s working and has worked for me in my journey. So I hope this has been helpful!
And as always, Happy Building!


