

Propagating changes in an event-driven system can be accomplished in many different ways with many different tools. Do I work with transaction logs, put events on an event bus or do something else? Fortunately, when storing data in AWS’ DynamoDB I can take advantage of the DynamoDB streams feature. DynamoDB Streams gives me an iterator that I can read from to publish or process item-level changes outside of the transaction of persisting the data from the originating client. I’ve written about streams before, here, here and here but in this article I want to look at DynamoDB Streams and Rust.
DynamoDB Streams and Rust
The scope of this article is going to highlight how to use Rust to receive and serialize the DynamoDB Change Records which can ultimately be used for further processing. Visually, that looks like this.
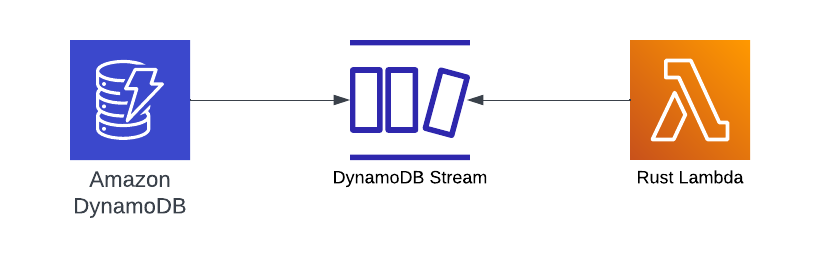
Code Walk through
Let’s explore a repository that highlights how to work with DynamoDB Streams and Rust. All of the samples in this article can be found here.
Infra Structure Setup
Setting up the infrastructure for this example will take advantage of the AWS CDK and TypeScript. I know there are comments and opinions out there that using Rust with Lambda feels odd when infrastructure code is in another language and I sort of agree, but TypeScript for building resources hopefully isn’t too taxing.
When deployed, my infrastructure will include:
- A DynamoDB Table
- A Stream enabled on the Table
- Lambda handler coded in Rust to serde the payload into a struct
Defining the Table
A DynamoDB Streams and Rust Lambda article needs a table and the below TypeScript will create what’s required.
this._table = new Table(scope, "SampleStreamTable", {
billingMode: BillingMode.PAY_PER_REQUEST,
removalPolicy: RemovalPolicy.DESTROY,
partitionKey: { name: "Id", type: AttributeType.NUMBER },
tableName: `SampleStreamTable`,
stream: StreamViewType.NEW_IMAGE,
});
Note that I’m creating a single Partition Key defined as a Number and called Id. Additionally, I’m enabling streams and sending New Images into the pipeline.
Creating the Function
I wrote in a previous article about how much I enjoy using Cargo Lambda which is a sub command of the Cargo tool. I also find using the CDK Construct when creating Rust Lambda functions to be convenient and familiar. If I dig into the source, it reveals that it is subclassing the Lambda function construct and adding the cross-compilation pieces for creating a Rust and Lambda bundle.
let sampleFunction = new RustFunction(scope, "SampleFunction", {
manifestPath: './',
architecture: Architecture.ARM_64,
functionName: 'sample-ddb-stream-handler',
memorySize: 256
})
With the infrastructure in place, let’s dive into the Rust code!
DynamoDB Streams and Rust Code
My DynamoDB Streams and Rust Lambda handler starts with a main function. Leveraging the Tokio macro enables my main function to use an asynchronous handler for dealing with Lambda events. For a deeper dive into Tokio and asynchronous workloads in Rust, follow that link.
#[tokio::main]
async fn main() -> Result<(), Error> {
tracing_subscriber::fmt()
.with_env_filter(
EnvFilter::builder()
.with_default_directive(LevelFilter::INFO.into())
.from_env_lossy(),
)
.json()
.with_target(false)
.without_time()
.init();
run(service_fn(function_handler)).await
}
The Handler
I didn’t want to focus too much on what to do with the data received so the handler is vanilla. It loops the requests, serdes each item in the payload into a struct and then prints out the record.
async fn function_handler(event: LambdaEvent<Event>) -> Result<(), Error> {
info!("(BatchSize)={:?}", event.payload.records.len());
// Extract some useful information from the request
for record in event.payload.records {
let m: SampleModel = record.change.new_image.into();
info!("(Sample)={:?}", m);
}
Ok(())
}
One thing to note, I’m using a fairly nice-sized batch setting when pulling from DDB. That setting is 100 records per pull in the example repos. This is where using Rust in a Lambda really shines because it’s not an I/O type operation. One can argue that everything waits at the same duration but processing JSON into a struct is always going to fly with Rust.
For example, here are some metrics when working with a batch of 100 and pulling in 45 records at a time.


Serde
Traits in Rust are similar to interfaces in other languages. It’s a way to group common behaviors so that I can treat structs that similarly implement those behaviors. Rust traits do have some nuance like being able to implement traits for types I didn’t define, but in general traits group behaviors. And one of those behaviors that I use a great deal is into(). When a type implements the From trait then I can use into() to convert that type into another. It’s a strongly-typed cast so to speak.
When working with DynamoDB change records, I needed to convert the record into my sample struct. This a simple example to illustrate the behavior, but think of it as taking one record layout and converting it to another.
impl From<Item> for SampleModel {
fn from(value: Item) -> Self {
let id_attr = value.get("Id");
let message_attr: Option<&AttributeValue> = value.get("Message");
let entity_type_attr: Option<&AttributeValue> = value.get("EntityType");
let mut id = 0;
let mut message = String::new();
let mut entity_type = String::new();
if let Some(AttributeValue::N(n)) = id_attr {
if let Ok(i) = n.parse::<i32>() {
id = i;
}
}
if let Some(AttributeValue::S(s)) = entity_type_attr {
entity_type = s.clone();
}
if let Some(AttributeValue::S(s)) = message_attr {
message = s.clone();
}
return SampleModel {
id,
message,
entity_type
}
}
}
The above code fetches values from the Item Hashmap and tries to perform conversions to return the SampleModel. I could have implemented TryFrom and returned a Result but this is an example code that might or might not be required in your use case.
Putting it All Together
In creating a DynamoDB Streams and Rust example, I could have just shown you how to add items to the table in the console and stopped there. But I decided against that. This example includes a Node.js script for running a chunk of PutItem operations against the DynamoDB table. When you clone the repository, there will be a scripts directory. That directory holds a file called sample-data.js. That file expects two variables to be configured.
DYNAMODB_ACCESS_KEY_IDwhich is the AWS access key that has rights to the tableDYNAMODB_SECRET_ACCESS_KEYwhich is the AWS secret access key that has rights to the table
Before running the script, you’ll need to deploy the infrastructure code. As I mentioned at the beginning, since this is a CDK project that can be accomplished by running this command.
cdk deploy
With those values set, you can decide how many records you want to persist by updating the for loop in that file. Then ultimately run this command which will start putting records in the table and the Lambda deployed will start processing the steam.
node sample-data.js
Wrapping Up
Using Rust in Lambda to process DynamoDB Streams is a safe and highly-performant way to deal with Change Data Capture in an event-driven system. I’m going to continue sharing small but targeted samples like this going forward as it relates to Rust because I believe that this type of content is a missing link in the Rust and Serverless ecosystem.
If you are looking for something just a little different when building your Serverless compute code, Rust is where you need to be looking. I get it, it looks a little funny. What’s with the :``:, dyn and ? among many other little syntactical quirks? But I promise you that leaning in just a little will pay you huge dividends as you ship Rust-coded Lambdas. Your code will be safe, it’ll be readable and it’ll be blazingly fast. Your users will thank you.
I strongly believe in the Rust language and ecosystem and even further believe in pairing it with Lambda. And if I can help just one person adopt the language this year, I’m going to be thrilled!
More to come on Rust and Lambda event processing but I hope you’ve seen how straightforward it is to process DynamoDB Streams with Rust and Lambda.
Thanks for reading and happy building!


