

I’ve been working recently with some data that doesn’t naturally fit into my AWS HealthLake datastore. I have some additional information captured in a DynamoDB table that would be useful to blend with HealthLake but on its own is not an FHIR resource. I pondered on this for a while and came up with the idea of piping DynamoDB stream changes to S3 so that I could then pick up with AWS Glue. In this article, I want to show you an approach to building a partitioned S3 bucket from DynamoDB. Refining that further with Glue jobs, tables and crawlers will come later.
Tag: golang

WebSocket with AWS API Gateway
I was working recently with some backend code and I needed to communicate the success or failure of the result back to my UI. I instantly knew that I needed to put together a WebSocket to handle this interaction between the backend and the front end. With all the Serverless and non-Serverless options out there though, which way do I go? How about plain old WebSockets with AWS API Gateway and Serverless?

DynamoDB Streams EventBridge Pipes Multiple Items
I’ve written a few articles lately on EventBridge Pipes and specifically around using them with DynamoDB Streams. I’ve written about Enrichment. And I’ve written about just straight Streaming. I believe that using EventBridge Pipes plays a nice part in a Serverless, Event-Driven approach. So in this article, I want to explore Streaming DynamoDB to EventBridge Pipes with multiple items in one table.
Several of the comments I received about Streaming DynamoDB to EventBridge Pipes were around, “What if I have multiple item collections in the same table?”. I intend to show a pattern for handling that exact problem in this article. At the bottom, you’ll find a working code sample that you can deploy and build on top of. I’ve used this exact setup in production, so rest assured that this is a great base to start from.

DynamoDB Streams EventBridge Pipes Enrichment
I’ve been wanting to spend more time lately talking about AWS HealthLake. And then more specifically, Fast Healthcare Interoperable Resources (FHIR) which is the foundation for interoperability in healthcare information systems. I believe very strongly that Serverless is for more than just client and user-driven workflows. I wrote extensively about it here but I wanted to take a deeper dive into building out streams of dataflows. I’ve been using this pattern for quite some time in production, so let’s have a look at EventBridge Pipes enriching DynamoDB Streams.

AWS Step Functions Callback Pattern
Some operations in a system function asynchronously. Many times, those same operations must also happen to be responsible for coordinating external workflows to provide an overall status on the execution of the main workflow. A natural fit for this problem with AWS is to use Step Functions and make use of the Callback pattern. In this article, I’m going to walk through an example of the Callback pattern while using AWS’ HealthLake and its export capabilities as the backbone for the async job. Welcome to the AWS Step Functions Callback Pattern.
Callback Workflow Solution Architecture
Let’s first start with the overarching architecture diagram. The general premise of the solution is that AWS’ HealthLake allows the export of all resources “since the last time”. By using Step Functions, Lambdas, SQS, DynamoDB, S3, Distributed Maps and EventBridge I’m going to build the ultimate Serverless Callback workflow. I feel like outside of Kinesis and SNS, I’ve touched them all in this one.
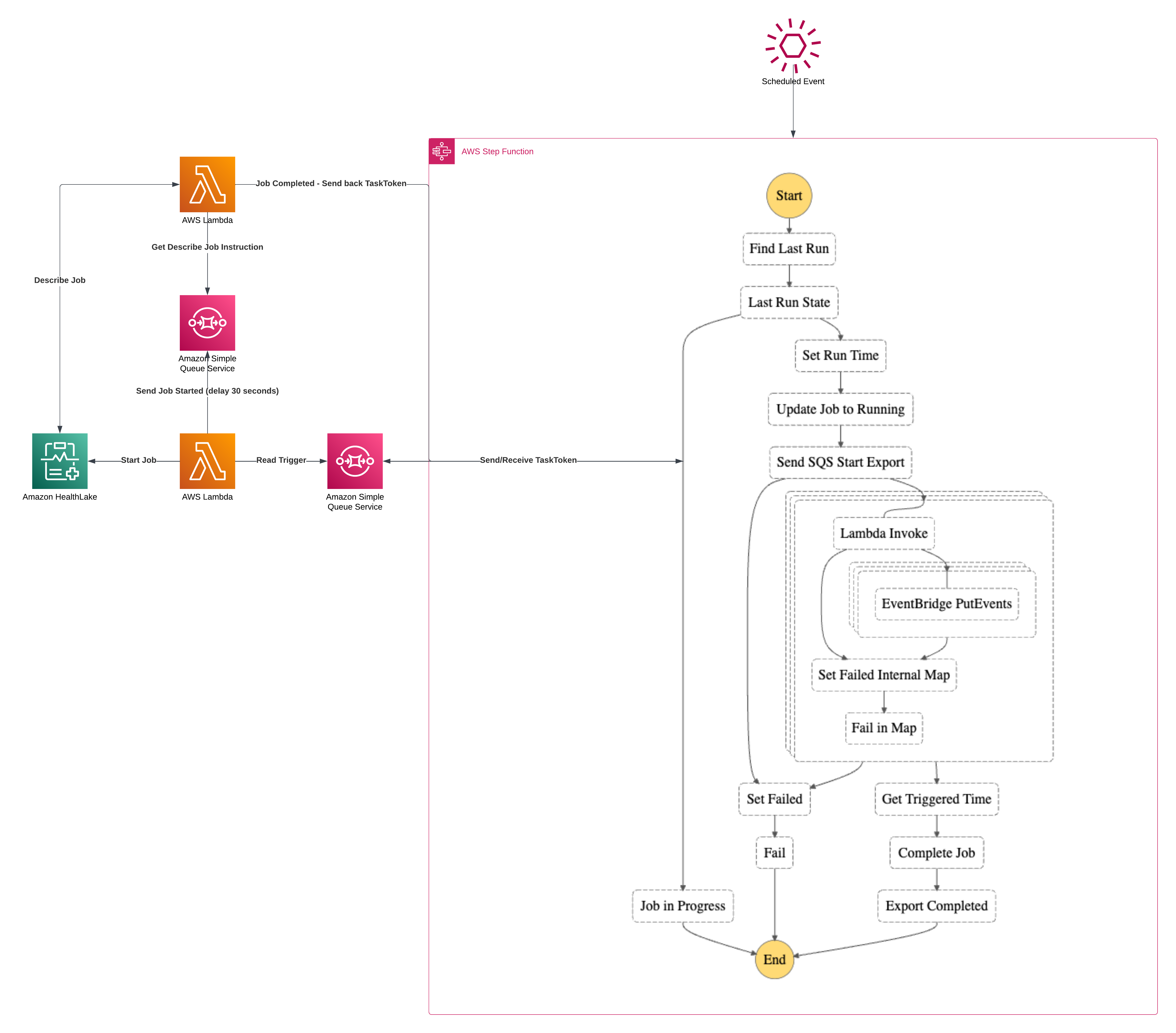
There’s quite a bit going on in here so I’m going to break it down into segments which will be:
- Triggering the State Machine
- Record Keeping and Run Status
- Running the Export and initiating the Callback
- Polling the Export and Restarting the State Machine
- Working the results
- Wrapping Up
- Dealing with Failure
Hang tight, there’s going to be a bunch of code and lots of detail. If you want to jump to code, it’s down at the bottom here

CategoriesServerless
Lambda Extension with Golang
For full disclosure, I’ve been writing Lambda function code since 2017 and I completely breezed over the release of Lambda Extensions back in 2020. Here’s the release announcement. At the core of extensions, you have internal and external options. For the balance of this article, I’m going to focus on building a Lambda extension with Golang and lean into the external style approach.
Extensions and Why
Taking a quick step back, why extensions? From an architect level of thinking, extensions give me the ability to have cross-team reuse of code without being tied to a particular language or build process. For something like Node or Python, you could use a standard Layer to package your Lambda reuse. But for something like Golang, where your code is packaged at build time and not run-time, then you sort of have to look at the shared library. I wrote about that here. But what if you wanted to create some shared functionality that was usable regardless of which language you built your Lamabda in? That seems to have some serious appeal for my current projects where teams are using different stacks to build their APIs due to need and comfort.

SQS Re-Drive with Golang and Step Functions
Earlier this week a new set of APIs were released for working with Dead-Letter-Queues and re-drives back to its primary queue. Messaging-based systems have been around for a long time and they are a critical piece of modern Event-Driven Architecture. As I read more about the APIs, I started thinking about how I could build up a sample that could be used for starting a hardened auto-re-drive State Machine that could put messages back on queues protected behind an API Gateway or Event Bridge Scheduler. Below is my take on how I might start thinking through building an SQS re-drive with Golang and Step Functions

CategoriesServerless
Caching with Momento and Golang
Caching. Simple. Useful. This architectural topic applies to a serverless app as well as an app with servers. Some functions never need caching, and some benefit from it right as the first user traffics some data through it. I’ve used a variety of caching tools over the years but recently dropped Momento’s serverless cache in a real-time ETL application and I was astonished at how easy it was and how well it is performing. This article is a walk-through of my experience of Caching with Momento and Golang.

Golang Private Module with CDK CodeBuild
Even experienced builders run into things from time to time that they haven’t seen before and this causes them some trouble. I’ve been working with CDK, CodePipeline, CodeBuild and Golang for several years now and haven’t needed to construct a private Golang module. That changed a few weeks ago and it threw me, as I needed to also include it in a CodePipeline with a CodeBuild step. This article is more documentation and reference for the future, as I want to share the pattern learned for building Golang private modules with CodeBuild.

Custom API Gateway Authorizer with Golang
One of the nice things about building with Serverless is that you can design things in a way that the pieces are composeable. This means that you can put logic cohesively with other like-minded logic and then keep things loosely coupled from other components so that things are easy to change without being too fragile. When building an API, you often need an Authorizer of sorts to validate the token that is being supplied. In this article, I’m going to walk through building a custom API Gateway Authorizer with Golang.