

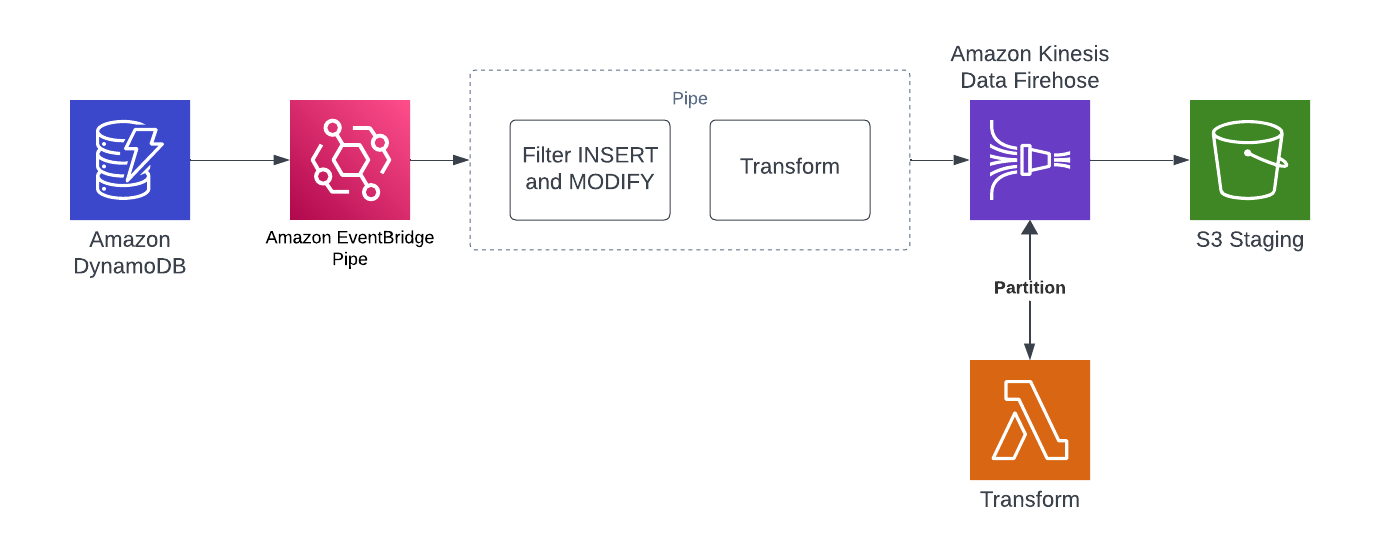
I’ve been working recently with some data that doesn’t naturally fit into my AWS HealthLake datastore. I have some additional information captured in a DynamoDB table that would be useful to blend with HealthLake but on its own is not an FHIR resource. I pondered on this for a while and came up with the idea of piping DynamoDB stream changes to S3 so that I could then pick up with AWS Glue. In this article, I want to show you an approach to building a partitioned S3 bucket from DynamoDB. Refining that further with Glue jobs, tables and crawlers will come later.
Architecture
What I like about this approach is that it’s Serverless. Nothing to manage and nothing to provision ahead of time. Everything in this stack expands or collapses based on the need.
In addition, it builds upon some of the topics I’ve covered on the blog before, so there are plenty of examples and repos to extend. Most recently with this DynamoDB and EventBridge Pipes Stream example.
Setting up the Problem
Back to the original need for this pattern. Sometimes you will have data stored in DynamoDB that you will want to report on. And as much as I love DDB, it’s not what I’m choosing to handle most reporting workloads. Second, a very reliable and scalable way to organize data before it is refined into useful information is to leverage a Data Lake. And lastly, before you can start refining that data, you need it to land somewhere and preferably organized in some format.
For the balance of the article, I’m going to walk through some TypeScript CDK code and Golang to build this reliable data staging pipeline.
Partitioned S3 bucket from DynamoDB
DynamoDB Table
The TableConstruct builds a simple table with PAY_PER_REQUEST pricing, a customer-managed KMS and a single PARTITION_KEY.
this._table = new Table(this, id, {
billingMode: BillingMode.PAY_PER_REQUEST,
removalPolicy: RemovalPolicy.DESTROY,
partitionKey: { name: "id", type: AttributeType.STRING },
tableName: `AnalyticsTable`,
encryption: TableEncryption.CUSTOMER_MANAGED,
encryptionKey: props.key,
stream: StreamViewType.NEW_AND_OLD_IMAGES,
});
Below are a couple of sample records that I’m going to be working with.
{
"valueOne": 123,
"siteId": "2",
"createdAtTime": 1700076551926,
"valueTwo": 6789,
"id": "123",
"name": "Name one"
}
{
"valueOne": 782,
"siteId": "1",
"createdAtTime": 1700076551318,
"valueTwo": 152,
"id": "456",
"name": "Name one"
}
Shaping with EventBridge Pipes
Shaping the output of a DynamodDB stream is straightforward when using EventBridge Pipes. I wrote an extensive article here about how to do that, so I won’t go into too much detail but do want to highlight the approach.
Defining the Pipe
Below is the TypeScript code that builds the pipe. With some of the other targets such as EventBridge or SQS, there are target parameters to specify. In the case of using Firehose that isn’t required. In replacement of that, I’m just inlining the input template for the target itself. That input template is present in all of the other specific targets as well and it gives me the chance to shape the DDB stream input into my format.
const pipe = new CfnPipe(scope, "Pipe", {
name: "Ddb-Stream-Firehose-Pipe",
roleArn: pipeRole.roleArn,
// eslint-disable-next-line @typescript-eslint/no-non-null-assertion
source: props.table.tableStreamArn!,
// enrichment: props.enrichmentFunction.functionArn,
target: props.firehose.attrArn,
targetParameters: {
inputTemplate: '{ "createdAtTime": "<$.dynamodb.NewImage.createdAtTime.N>", "siteId": "<$.dynamodb.NewImage.siteId.S>", "id": "<$.dynamodb.NewImage.id.S>", "name": "<$.dynamodb.NewImage.name.S>", "valueOne": "<$.dynamodb.NewImage.valueOne.N>", "valueTwo": "<$.dynamodb.NewImage.valueTwo.N>" }'
},
sourceParameters: this.sourceParameters(),
Also, don’t skip over the IAM permissions the pipe will need for issuing a Direct PUT into Kinesis Firehose. I could have been lazy and used kms:* or firehose:* but that isn’t very secure 🙂
return new PolicyDocument({
statements: [
new PolicyStatement({
sid: "KMSPolicy",
actions: [
"kms:Decrypt",
"kms:DescribeKey",
"kms:Encrypt",
"kms:GenerateDataKey*",
"kms:ReEncrypt*",
],
effect: Effect.ALLOW,
resources: [props.key.keyArn],
}),
new PolicyStatement({
sid: "FirehosePolicy",
actions: [
"firehose:DeleteDeliveryStream",
"firehose:PutRecord",
"firehose:PutRecordBatch",
"firehose:UpdateDestination",
],
effect: Effect.ALLOW,
resources: [props.firehose.attrArn],
}),
],
});
The Stream
In all transparency, I don’t use Firehose that often so I was excited to leverage it for building a partitioned S3 bucket from DynamoDB. I LOVE Kinesis in general and make use of Data Streams frequently but just don’t use Firehose much.
The main thing to understand about Firehose is that it’s a little like Pipes in that you have opportunities to shape and transform data as it flows through the system. You also have a few ways to ingest data and for this example, I’m going to make use of the generic Direct PUT option.
Since I haven’t done an article on Firehose before, I want to break down this CDK code a little bit, specifically the Props that set up the stream. The construct I’ll be leveraging is an L2 defined as CfnDeliveryStream. Documentation
Top-Level Properties
Top-level properties give me the option to name the stream and choose the stream type. Remember above I mentioned Direct PUT and that’s because the source of EB Pipes is not a native integration. Which is why the Direct PUT option exists.
deliveryStreamName: "analytics",
deliveryStreamType: 'DirectPut',
Encryption
The encryption configuration should seem pretty obvious. I’m leveraging the shared KMS Key I built in the stack. And then for the stream, specifying that it’s a CUSTOMER_MANAGED_CMK
deliveryStreamEncryptionConfigurationInput: {
keyArn: props.key.keyArn,
keyType: "CUSTOMER_MANAGED_CMK",
},
S3 Output Destination
The output is where this gets fun. Building a partitioned S3 bucket is natively supported in Firehose. Quick aside, why does partitioning matter? A couple of key things.
- Data organization
- Data query performance
The extendedS3DestinationConfiguration can be a little long to build, but let me highlight some key pieces.
- bufferingHints: The right interval and size take a little bit of art and science. For small samples of data, it doesn’t matter much, but performance can be impacted or improved by tweaking these.
- roleArn: In the repository, you’ll see the specific permissions you need, but the role matters.
- prefix: The bucket prefixing that’ll take place in S3. There are a few options to leverage, but in my example, I’m picking up these dynamic partitions from my Lambda. I’m structuring it like this
site=1/year=2023/month=11/day=17/minute=32/<some data>dynamicPartitioningConfiguration: to support this partitioning, I need to enable dynamic partitioning. - processingConfiguration: Firehose supports in-line (jQ) based processing or you can use a Lambda function. In most cases, I’d like to use jQ, but for this example, I went with a Lambda
extendedS3DestinationConfiguration: {
bucketArn: props.bucket.bucketArn,
bufferingHints: {
intervalInSeconds: 60,
sizeInMBs: 128
},
encryptionConfiguration: {
kmsEncryptionConfig: {
awskmsKeyArn: props.key.keyArn
}
},
roleArn: role.roleArn,
prefix: 'data/siteId=!{partitionKeyFromLambda:siteId}/year=!{partitionKeyFromLambda:year}/month=!{partitionKeyFromLambda:month}/day=!{partitionKeyFromLambda:day}/minute=!{partitionKeyFromLambda:minute}/',
errorOutputPrefix: 'errors/',
dynamicPartitioningConfiguration: {
enabled: true,
},
processingConfiguration: {
enabled: true,
processors: [{
type: "Lambda",
parameters: [
{
parameterName: "LambdaArn",
parameterValue: props.transformation.functionArn
},
]
}]
},
}
The Stream Lambda
As you can imagine, there isn’t a lot to the transformation Lambda code. I do want to showcase the structs that I’m working with that I hadn’t used before.
The signature of the handler is as follows:
func handler(ctx context.Context, firehose events.KinesisFirehoseEvent) (events.KinesisFirehoseResponse, error)
The best part of working with the events.KinesisFirehoseEvent is that it contains all of the records that the stream is holding in its buffer for processing. Then when packaging up my return payload, I can flag the records as success or failure so that I’m not dealing with any kinds of fractional failures and Poison Pill Messages.
err := json.Unmarshal(r.Data, &recordData)
if err != nil {
log.WithFields(log.Fields{
"err": err,
"recordID": r.RecordID,
}).Error("Error unmarshalling the record")
transformedRecord.Result = "ProcessingFailed"
response.Records = append(response.Records, transformedRecord)
continue
}
Additionally, I can build the dynamic partitions that I’ve shown as part of the bucket prefix.
partitionKeys["siteId"] = recordData.SiteId partitionKeys["year"] = strconv.Itoa(recordData.CreatedAtTime.Year()) partitionKeys["month"] = strconv.Itoa(int(recordData.CreatedAtTime.Month())) partitionKeys["day"] = strconv.Itoa(recordData.CreatedAtTime.Day()) partitionKeys["hour"] = strconv.Itoa(recordData.CreatedAtTime.Hour()) partitionKeys["minute"] = strconv.Itoa(recordData.CreatedAtTime.Minute())
Partitioned S3 Bucket
Since the example repository is using CDK, you can follow the directions in the README to install dependencies. Once you have all those configured, run.
cdk deploy
Your AWS Account should have the following resources configured.
- S3 Bucket
- DynamoDB Table
- Configured for streams
- EventBridge Pipe
- Filtering rule
- Target transformation
- Kinesis Firehose
- Direct PUT integration
- Transformation enabled using a Lambda
- KMS Key for encryption throughout
- Various IAM policies for the services
Let’s take a small tour.
Example Table
Here is the configured stream.

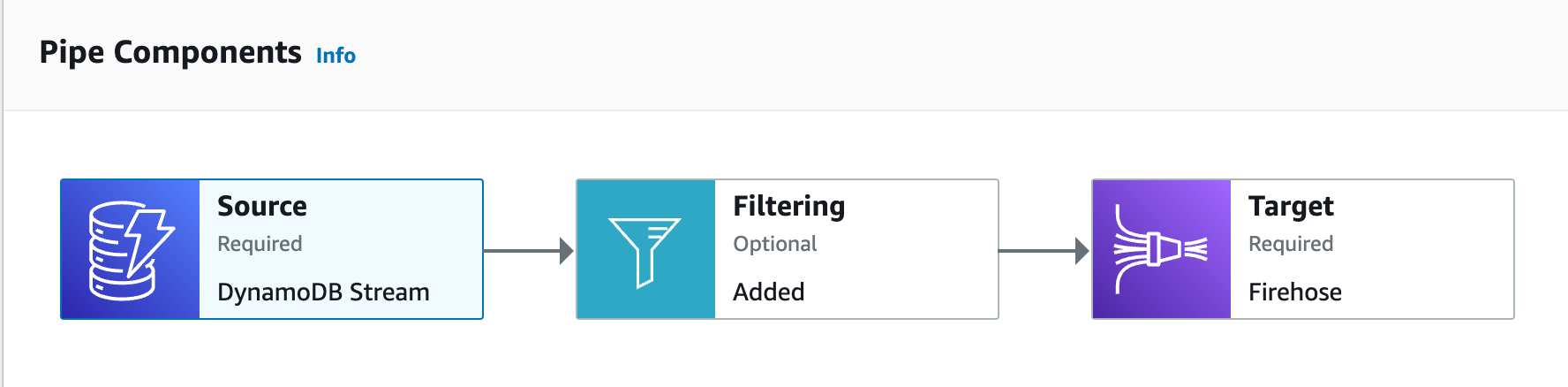
EventBridge Pipe
Overview of the components.
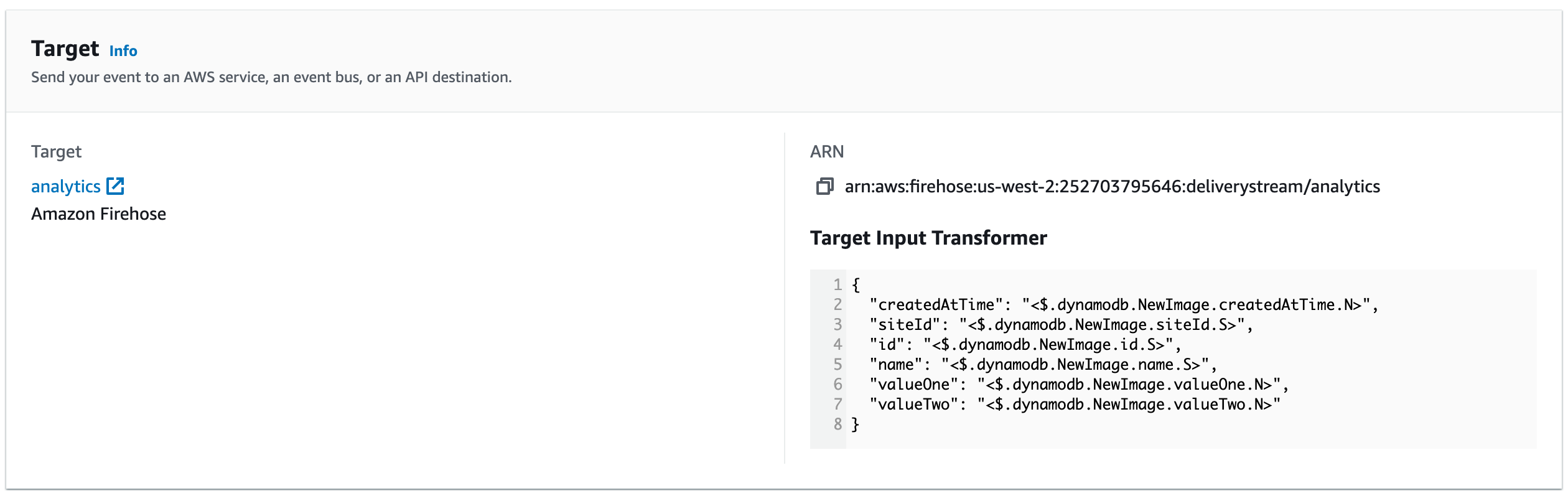
Transform and target.
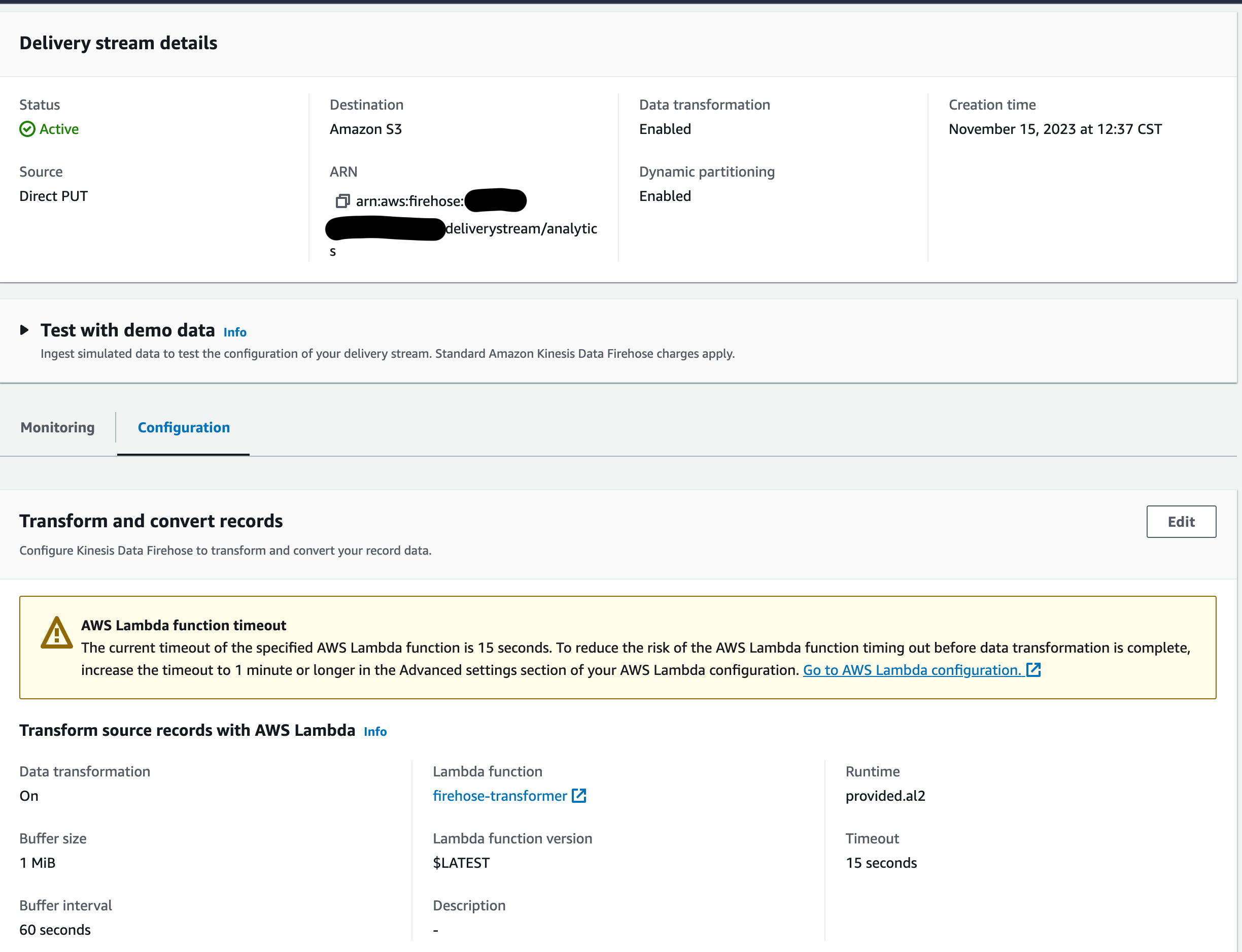
Kinesis Firehose
The configured Firehose stream
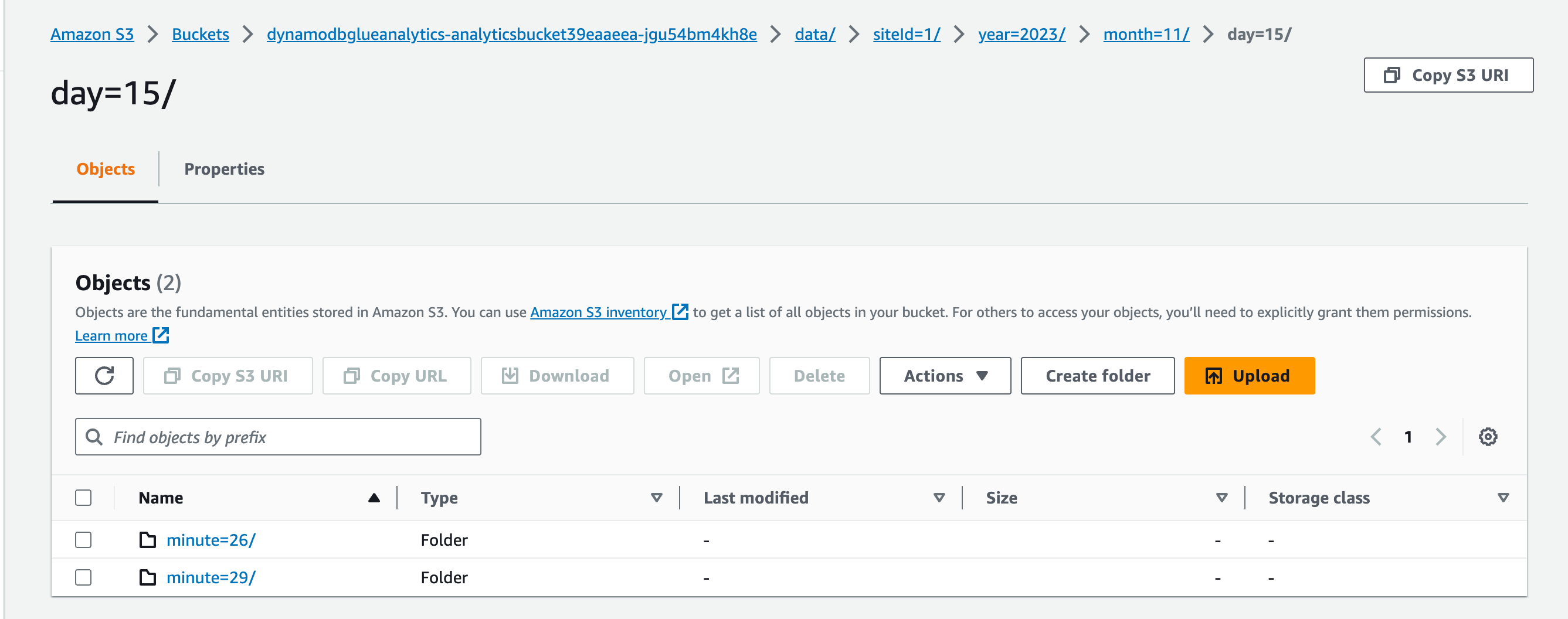
Partioned S3 Bucket from DynamoDB
And to wrap it all up, the partitioned S3 bucket populated from the DynamoDB source.
Wrap Up
Ultimately this is just part of a bigger solution that should include Glue Jobs, Tables and Crawlers plus Athena to power a more robust result. However, you can’t have analytics with preparing the data and step 1 is to acquire and organize it I hope you’ve seen a way to achieve this above. I would encourage you not to be afraid of some of these concepts as there are many ways to accomplish the above. Big data architecture and problem-solving are vast and have many paths to success. Start with what you are comfortable with and build from there. And ask questions along the way.
As with most of my articles, here is the sample repository. Feel free to clone it and adapt it to your needs. And when you are done, just run:
cdk destroy
Thanks for reading and happy building!


