

It’s been a few weeks since I last wrote an article on using Rust with AWS. In the span of then and now, AWS officially released their Rust SDK for interacting with many of their services. If there was a barrier before this in my mind about using something in production that wasn’t generally available, that barrier is now gone. I also made a public commitment to building more examples in Rust in 2024 and while I’m a few weeks early, I just can’t contain my enthusiasm for learning this language that feels nothing like anything I’ve worked with before. Let’s take a look at building an API with API Gateway, Lambda, DynamoDB and Rust.
Architecture
Like my previous Rust article, this one won’t be highly complex from a design standpoint. The purpose of this is to highlight how to use the SDK and navigate some of the language features. For these reasons, a simple AWS design will give me just the right balance of interactions with the platform to accomplish this.
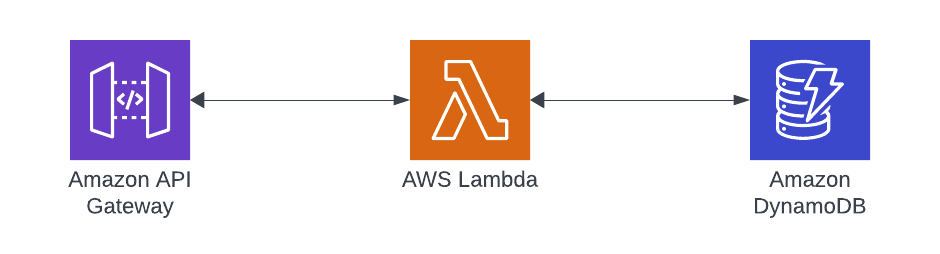
The use case I’ll be walking through is a GET request that routes through API Gateway to Lambda. That Lambda will then be coded in Rust and use the new AWS Rust SDK to interact with DynamoDB and return the results to the caller. Easy peasy.
Building an API with API Gateway, Lambda, DynamoDB and Rust
For the balance of the article, I’ll be diving into the code that makes this sample run. In addition, I’ll show some payloads and highlight things that I found important along the way.
Kicking off the tour and not starting a war, but I’m going to be using the Serverless Application Model.
SAM and Rust
A few months back, the AWS SAM team released “beta” support for Rust using Cargo Lambda. Cargo is the crate/library manager for Rust and this additional subcommand brings in a lot of additional functionality. Per the Cargo Lambda team:
Cargo Lambda is a subcommand for Cargo, the Rust package manager, to work with AWS Lambda. Cargo Lambda provides tools and workflows to help you get started building Rust functions for AWS Lambda from scratch. When you’re ready to put your work in production, Cargo Lambda helps you build and deploy your functions on AWS Lambda in an efficient manner. – Cargo Lambda
With SAM I can define the AWS resources I need and simply provision the access to each that the other requires. Additionally, I can use the CLI that allows for easy building and deployment. Between SAM and Cargo Lambda, I’ve got all the tools to build and test my function locally and deploy to AWS.
SAM DynamoDB
When building an API with API Gateway, Lambda, DynamoDB and Rust, I need to define the DynamoDB.
For my example, I’m using a table with a Composite Key that has fields pk and sk which stand for PartitionKey and SortKey. I’m also using On Demand pricing which will cost a little more per request but doesn’t incur any cost to provision.
DynamoDBTable:
Type: AWS::DynamoDB::Table
Properties:
AttributeDefinitions:
- AttributeName: pk
AttributeType: S
- AttributeName: sk
AttributeType: S
KeySchema:
- AttributeName: pk
KeyType: HASH
- AttributeName: sk
KeyType: RANGE
BillingMode: PAY_PER_REQUEST
StreamSpecification:
StreamViewType: NEW_IMAGE
SAM Function and Rust
A function definition in SAM allows me to attach the event triggers as well. In this instance, API Gateway will be my trigger. The single endpoint that I’m defining will respond to a GET request on the path /{id}.
GetByIdFunction:
Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction
Metadata:
BuildMethod: rust-cargolambda # More info about Cargo Lambda: https://github.com/cargo-lambda/cargo-lambda
Properties:
Environment:
Variables:
TABLE_NAME: !Ref DynamoDBTable
CodeUri: . # Points to dir of Cargo.toml
Handler: bootstrap # Do not change, as this is the default executable name produced by Cargo Lambda
Runtime: provided.al2
FunctionName: get-by-id
Architectures:
- arm64
Policies:
- DynamoDBCrudPolicy:
TableName: !Ref DynamoDBTable
Events:
GetById:
Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api
Properties:
Path: /{id}
Method: get
Rust Specific Sections
I want to take a closer look at the Rust-specific pieces of this. Remember, the Rust support is “beta” and to enable it you either need to use sam build --beta-features or enable it in the samconfig.toml file.
That looks like this in the samconfig.toml file:
[default.build.parameters] # Rust Support for Cargo Lambda beta_features = true
[default.sync.parameters]
# Rust Support for Cargo Lambda beta_features = true
First, the MetaData section has a BuildMethod property. And that property is telling SAM to use Cargo Lambda as the build mechanism.
Metadata:
BuildMethod: rust-cargolambda
Second, the Properties of the function matter.
The CodeUri needs to point to your Cargo.toml file. I’m setting this up as a multi-function template, so I’m using the workspace level Cargo.toml. However, if you were using a single function setup, you would point the CodeUri at that single Cargo.toml.
The Handler property points to the executable that will be created on the build.
Runtime is set to provided.al2 which is the Amazon Linux image. Small aside. If you find it confusing that there is no Rust runtime, let me offer this. When you build a Rust Lambda, it’s natively compiled to the chip architecture that you set. Why would you need a runtime as it’s just a binary? I think of deploying to AL2 an Amazon-managed environment that is purpose-built for running my binary code. I could use a Docker container, but I like as little friction as possible.
CodeUri: . # Points to dir of Cargo.toml
Handler: bootstrap # Do not change, as this is the default executable name produced by Cargo Lambda
Runtime: provided.al2
Architectures:
- arm64
The last thing to point out is that I’m using the ARM chipset which gives me access to Graviton and all of the benefits that doing so provides me.
Rust
With the release of the AWS SDK a few weeks back, AWS now has a production-ready toolkit for developers to interact with its components in a Rust-native way. Part of the biggest takeaways for me when learning Rust, is learning the Rust way to code. With any language that I undertake learning, I try hard to focus on how the language desires to be used to maximize the benefits of its promise.
Rust and Lambda
This part of the article is going to dive deep into what I know currently about Rust and blend my knowledge of DynamoDB and Lambda to highlight this experience.
Setting it Up
In Rust, main is just like in any other programming language. It’s the entry point to your code’s execution.
The AWS SDK makes use of the async capabilities in the Tokio library. So when you see async in front of a fn that function is capable of executing asynchronously.
#[tokio::main]
async fn main() -> Result<(), Error> {
tracing_subscriber::fmt()
.json()
.with_max_level(tracing::Level::INFO)
.with_target(false)
.init();
let stream = env::var("TABLE_NAME").unwrap();
let str_pointer = stream.as_str();
let config = aws_config::from_env()
.load()
.await;
let client = Client::new(&config);
let shared_client = &client;
run(service_fn(
move |event: LambdaEvent<ApiGatewayProxyRequest>| async move {
function_handler(&shared_client, str_pointer, event).await
},
))
.await
}
In my main I’m using the environment variables to pick up the Table Name to use when querying. When running Lambdas, the best practice is to initialize reusable components only once to save upfront execution time. And remember, time is money when it comes to executing Lambdas.
// shared client
let client = Client::new(&config);
let shared_client = &client;
run(service_fn(
move |event: LambdaEvent<ApiGatewayProxyRequest>| async move {
function_handler(&shared_client, str_pointer, event).await
},
))
.await
Lambda Handler
Building an API with API Gateway, Lambda, DynamoDB and Rust from a mechanical standpoint is the same as using any other language. Events happen and trigger a Lambda. The Lambda Handler is the function that will particularly deal with the event that triggers the Lambda’s execution. A Rust Lambda Handler is no different.
async fn function_handler(
client: &Client,
table_name: &str,
event: LambdaEvent<ApiGatewayProxyRequest>,
) -> Result<ApiGatewayProxyResponse, Error> {
let mut resp = ApiGatewayProxyResponse {
status_code: 200,
is_base64_encoded: Some(false),
body: Some(event.payload.path.unwrap().into()),
multi_value_headers: Default::default(),
headers: Default::default(),
};
match event.payload.path_parameters.get("id") {
Some(value) => {
tracing::info!("(Value)={}", value);
let item: Result<Item, ItemError> = fetch_item(client, table_name, value).await;
tracing::info!("Item retrieved now");
tracing::info!("(Item)={:?}", item);
let body = json!(item.unwrap()).to_string();
resp.body = Some(body.into());
}
None => {
tracing::error!("Key doesn't exist");
resp.status_code = 404;
}
}
Ok(resp)
}
Beyond this code looking very Rust-y, there’s not much in here going on. I’m setting up a response to return to the client.
One of the great language features of Rust is the use of Enums and Matching on those returned enum values. The ApiGatewayProxyRequest has a payload struct that contains a path HashMap. That HashMap then contains Option<> Values for the Path Keys. The Option is another Rust Enum that protects the developer from null and missing elements.
Then by leveraging match, I can safely execute my DynamoDB query OR I can mark the request as 404 to send back to the caller.
Models
For building an API with API Gateway, Lambda, DynamoDB and Rust, I wanted to showcase using structs as Data Models just as I would in another language or technology.
Separating your files in Rust includes using modules to organize your code.
In Rust, building Models is as simple as defining a struct.
#[derive(Serialize, Deserialize, Debug, DisplayAsJsonPretty)]
pub struct Item {
pk: String,
sk: String,
}
I’m defining a simple public struct that has a few macros defined for serde, debug and display. I’m not going to get into the specifics of macros, but the Rust documentation defines them as this.
Fundamentally, macros are a way of writing code that writes other code, which is known as metaprogramming – Rust
DynamoDB Retrieval
DynamoDB holds the on-disk representation of the model defined above. There have been various libraries and tools for accessing it with Rust, but the new SDK simplifies that greatly.
Using DynamoDB with Rust feels just like other parts of the Rust ecosystem. It makes use of Option, Async and Fluent Builders.
I’ve packaged this data access code in its file as well and looks like this.
pub async fn fetch_item(client: &Client, table_name: &str, id: &str) -> Result<Item, ItemError> {
// Building a Composite Key
let key_map: HashMap<String, AttributeValue> = [
("pk".to_string(), AttributeValue::S(id.to_string())),
("sk".to_string(), AttributeValue::S(id.to_string())),
]
.iter()
.cloned()
.collect();
// client returns Option for the result which might be Ok or might be Err
match client
.get_item()
.table_name(table_name)
.set_key(Some(key_map))
.send()
.await
{
Ok(result) => {
// levaraging serde_dynamo
let i: Item = from_item(result.item.unwrap())?;
Ok(i)
}
Err(e) => Err(e.into()),
}
}
The main things to take away from this code.
- A GetItem in DynamoDB is called by building a request through the builder pattern
- Sending the request makes use of the async capabilities
- The result is an Option that contains the result or an error that can be handled through the
match
Putting it all Together
The exercise here isn’t to showcase performance or scale but I do want to highlight the speed just a little bit. In addition, I’m using the path parameter as the key to look up the item in DynamoDB as shown above.
My table contains a single record with the composite key of pk and sk. That item looks like this.

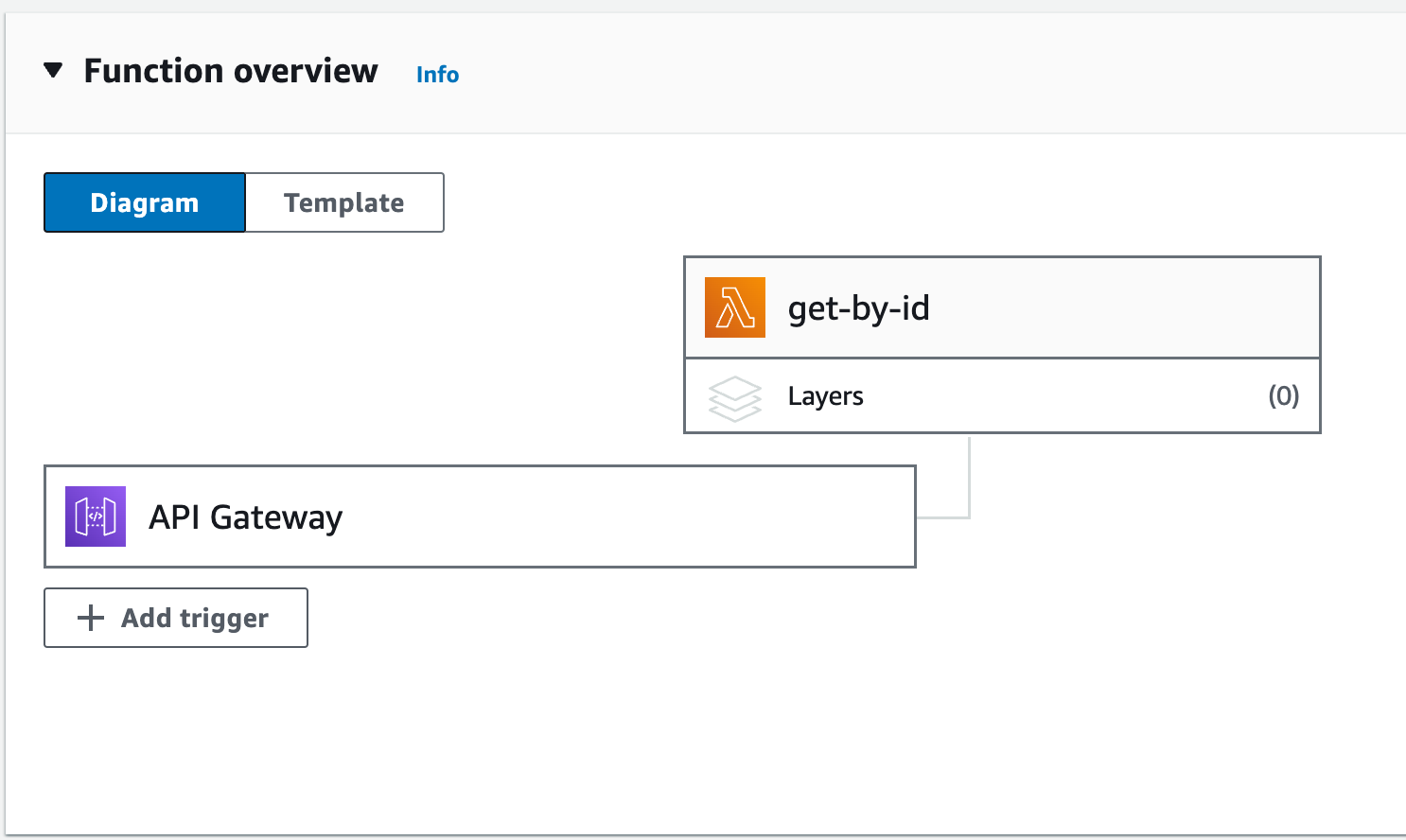
Building an API with API Gateway, Rust, DynamoDB and Lambda requires the Lambda and when deployed, the AWS Console shows the function and the API Gateway triggering event.
And with those two pieces in place, I can execute a request in Postman.
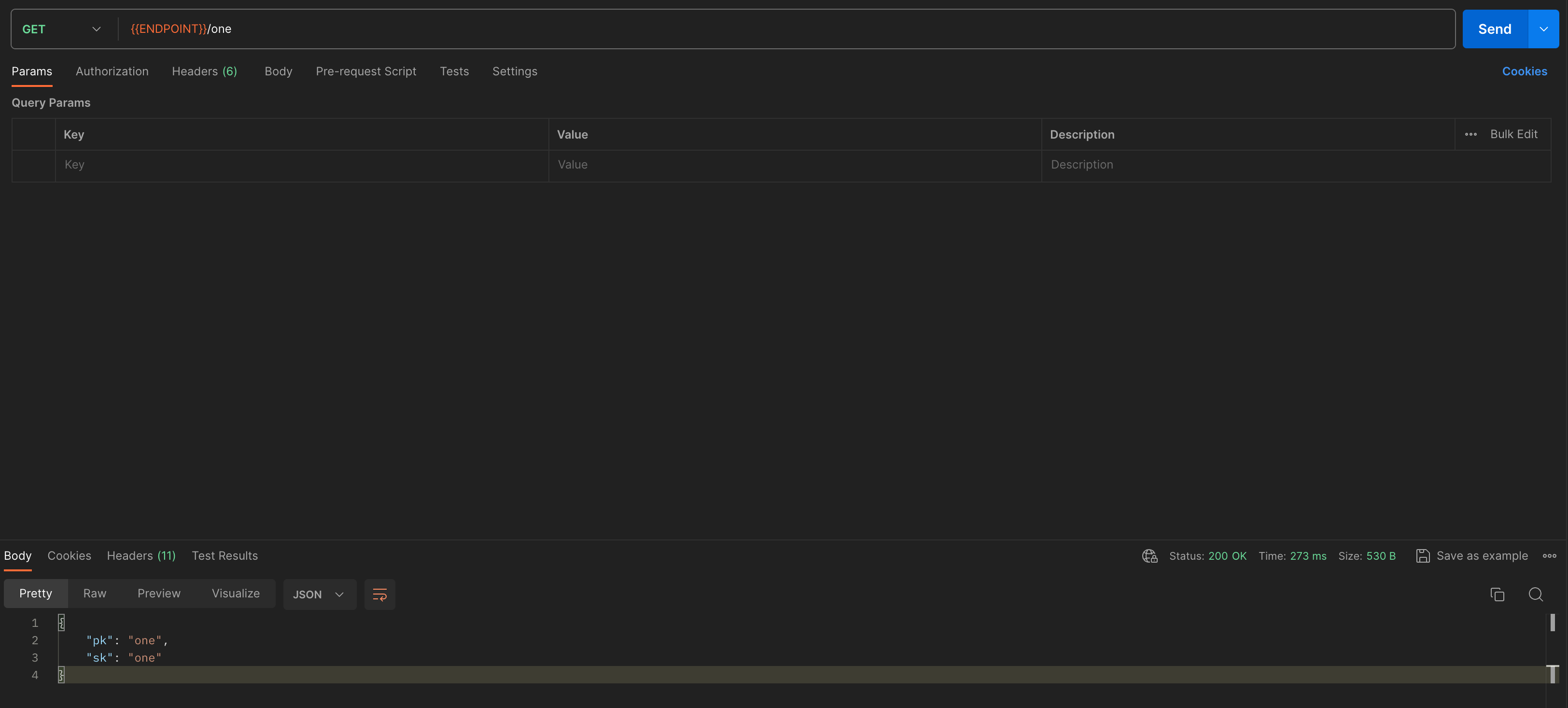
It feels like a long journey through all of this code, but in the end, it’s just an HTTP GET that returns some JSON.
Touch on Performance
Rust is often touted as being a more performant language to run than some of its competitors. This is 100% factual in almost all cases. A recent study also highlights its energy efficiency as well which if you relate to Dr. Vogels’ keynote at re:Invent ’23, is a great approximation for cost.
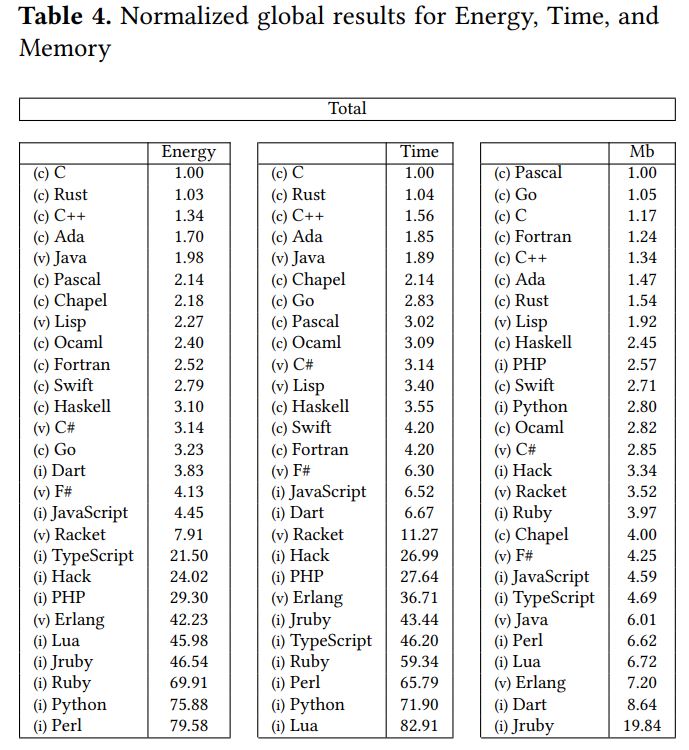
With all of that, I wanted to run some simple load against my Lambda to see how well it performed. Remember, this handles a GET event from API Gateway, deserializes it, executes a DynamoDB request, serializes it back to JSON and then returns. The final binary size is also around 4MB which is tiny compared to every other Lambda zip package I’ve shipped before.
Here are those metrics per the AWS Console
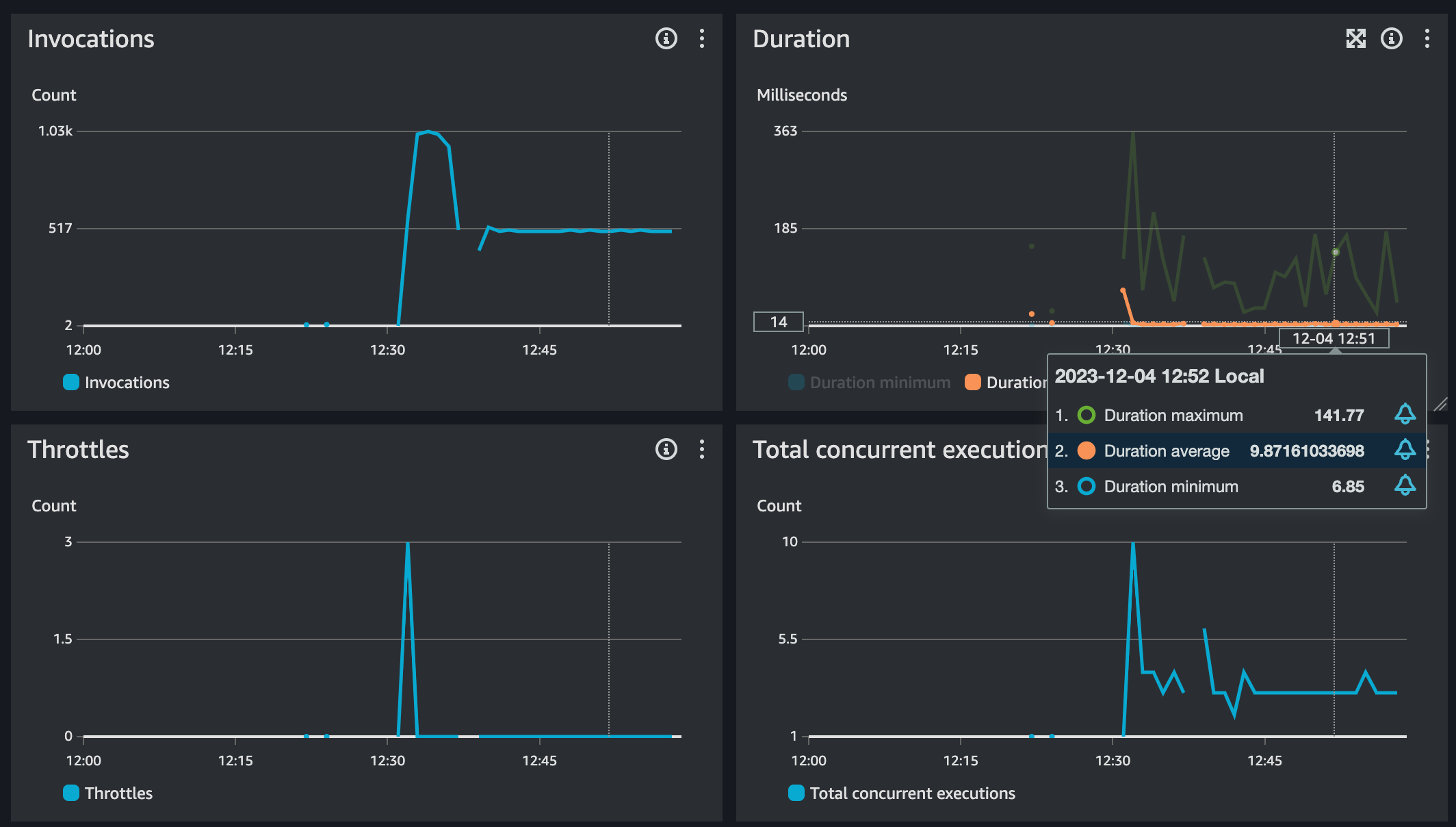
These are small samples and over a brief period. However, < 10ms average duration is nothing to sneeze at and with the minimum duration so close, I can assume that most of the requests are within a handful of ms from each other. Those green spikes are the cold starts, which by the way are relatively much faster than anything I’ve seen before either doing the same workload. I’ll run some side-by-sides soon with Go and TypeScript just for fun with the same 128MB settings.
Wrapping Up
I have to admit, I’ve become enamored with this language and the ecosystem. The syntax and some of the constructs still seem odd, but I’m learning and improving each time I code in Rust. I’m also happy that I can do all of this easily from VSCode in an editor that feels familiar because I use it everywhere else.
I’ve promised my team I won’t push Rust on them like I did Go. I find transitioning to Go to be easy and not a hard leap. Rust however has taken me months on and off to even start to feel productive. I can say with certainty, that the reasons for moving and trying the language are worth it in my opinion. When building Serverless applications, time is money and resources aren’t truly infinite. And by leveraging a language that gets the most out of my compute, I feel that I can pass that reduction in cost back to my customers. And as for sustainability, who isn’t for using less if you don’t need more.
And as always, here’s the repository that is fully working and can be cloned and deployed in your environment.
Thanks for reading and happy building!


