
Serverless architecture has given developers, architects, and business problem solvers new capabilities to deliver value to customers. It feels like we are in the age of maturation of serverless in so many ways. The boom of containers, the birth of functions, and now the options of even Zero-code serverless implementations (Step Functions). These are all great things from an application developer’s perspective. But what about reporting? There are so many signals emitted from these systems but has the reporting world kept up with the changes in architecture? And what are some strategies to take advantage of data in this current landscape? Let’s have a look at Reporting with Serverless.
Architecture
Let’s take a look at a small but fairly typical architecture that I see quite often. I have strong opinions that each microservice boundary should have its database. That could be an RDS instance, Aurora cluster, SQL Server, or multiple DynamoDB tables that it and only it can directly interact with. Any communication outside of this boundary with the data it owns has to happen through an event or an HTTP/gRPC API. I could diagram them like the below:
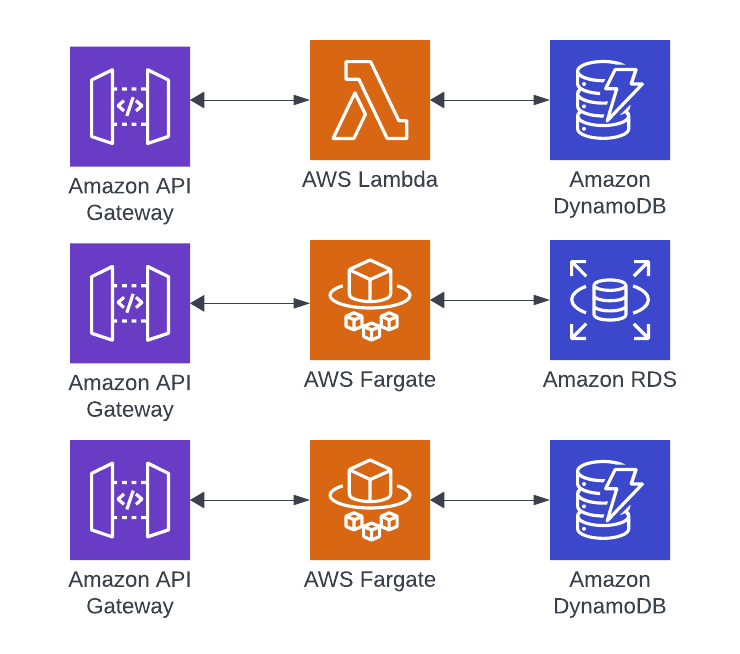
Now I do believe there is more to this topic that needs to further refine the context. The minute an application starts to silo its data is the minute that data replication or virtualization enters into the equation most of the time. Picture an enterprise business-to-business application that operates a large software solution broken up into 100 different parts. The challenges that exist for unifying that information are much different than the challenges of a consumer application that has a high volume but a low surface of data stores due to the nature of the application scope.
This is where thinking like a consultant comes into play when helping to figure out which kinds of problems need to be solved. But make no mistake, reporting with serverless is a problem that will need to be addressed. And to be clear, let’s outline exactly what that is.
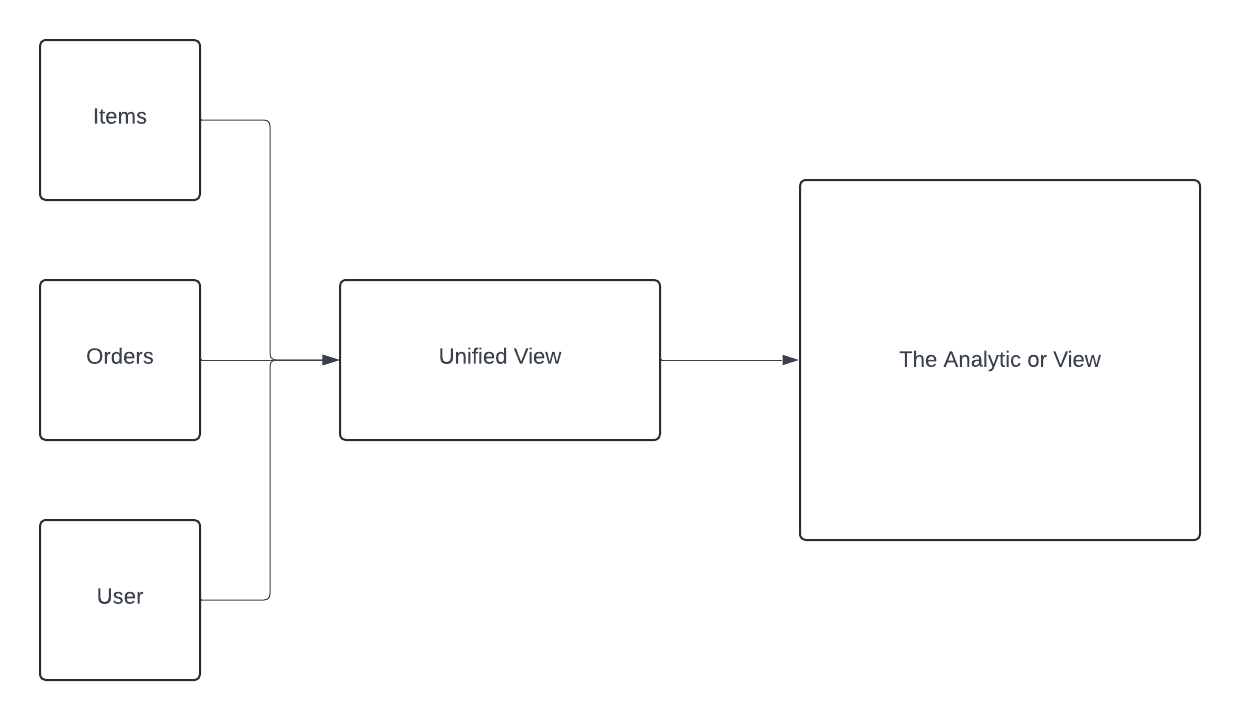
The scenario I’m writing about here is this. In your application, you will have multiple root-level entities that need to be viewed and aggregated in a unified result. That could be an analytic that counts the number of times a user placed an order or it might be to print a user’s last order that they made.
Our reference point for reporting with serverless is going to be this order, items, and user diagram.
3 Patterns for Reporting with Microservices
I’ve been working with serverless and microservices for 7 years now and have used some variations of the same 3 approaches to solve reporting with serverless in multiple problem domains. These patterns will serve as starting points as you begin to think about how to solve reporting with serverless.
I’d describe the patterns like this.
- Replicate to read
- Split for speed and read
- Eventually readable
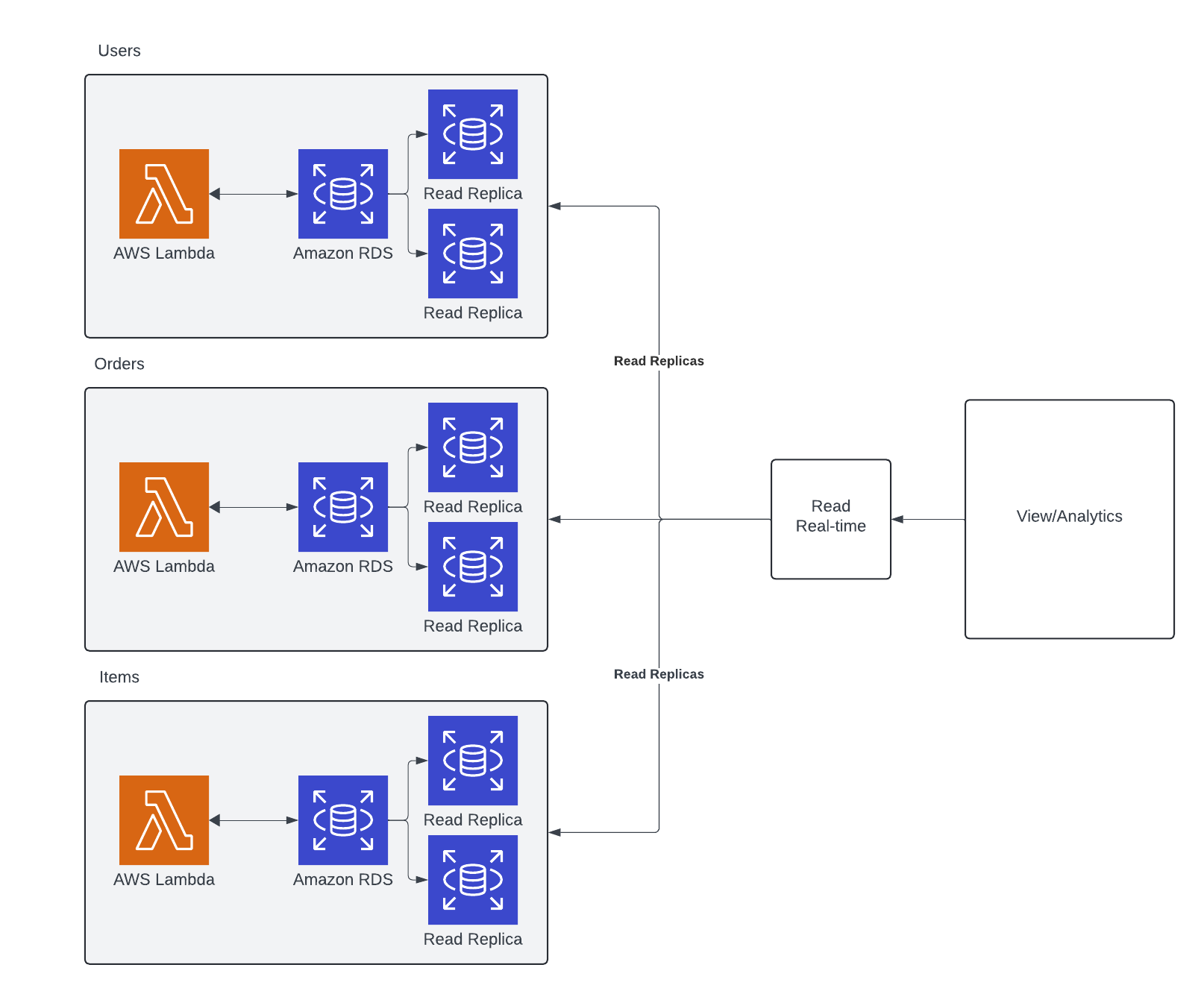
Replicate to Read
Solving for reporting with serverless can be done very simply if all of your data is stored in something that can handle dynamic queries like SQL. The beauty of a relational database management system (RDBMS) is that your data is not pre-optimized for the reads you will need but the system can be guided to make efficient queries based upon the hints you leave it. This is done with indexing.
In a scenario like this, your reporting and analytics solution can just go straight to the sources and pull the data it needs to generate the information required. This might feel similar to what’s been done before when the data was stored in a monolithic and singular database. And it 100% is.
The reason I call this pattern Replicate to Read is that it’s often advantageous to use Read Replicas to help with connection pooling and resource management to not clog the transactional system with analytics workloads.
Pros
The pros to the replicate-to-read pattern while solving reporting with serverless are as follows:
First, is its simplicity. In many cases, read replicas on the source may not even be needed and the system can get away with going directly to the primary tables. The reporting team can connect and get going. If there are problems that arise from this related to connection management or resource utilization, read replicas can be a great answer for solving this problem.
Second, speed. The data sits right next to the source and sometimes it is the source. This lack of transformation can be a serious boost because the data requires no hops to land in a final form.
Cons
While this pattern is great for speed and it is extremely simple, it does suffer from a few limitations.
The first of those data is not stored or optimized for reporting. Many RDBMS schemas are highly normalized and optimized for the workload of being transactional. This design sits in opposition to reporting schemas.
Next, the matter of blending these different datasets falls squarely on the reporting tool of choice. This often leads to complex reports, joins, and merges of datasets.
And lastly, connection management. The report needs to hit 3 separate systems and this all happens over the network. There’s a chance of failure and additional complexity which again falls on the reporting tool.
Wrap Up
The bottom line, this is a great option if the solution is built upon purely RDBMS technologies and the number of data sources is low. If this is as far as the system ever needs to go, then fantastic!
Split for Read and Speed
Reporting with serverless requires balancing requirements which should include things that generally get lumped into the non-functional category. How quickly the data is available is often a requirement.
Think for instance about our Orders and Users domain. The product owner might ask for the user to be able to print their order shortly after making it. Or that the order is available for download once the purchase is made. Going back to the replicate to read pattern, this would be a simple use case. However, let’s assume that one of the microservices is storing its data in DynamoDB
Remember, there is no one-size-fits-all here but chances are, the various needs and filters of a report will outgrow your ability to design and model your DynamoDB table. If the use cases are super simple, this might not happen, but in many cases, the data needs to be more queryable. So enter the Split for Read and Speed.
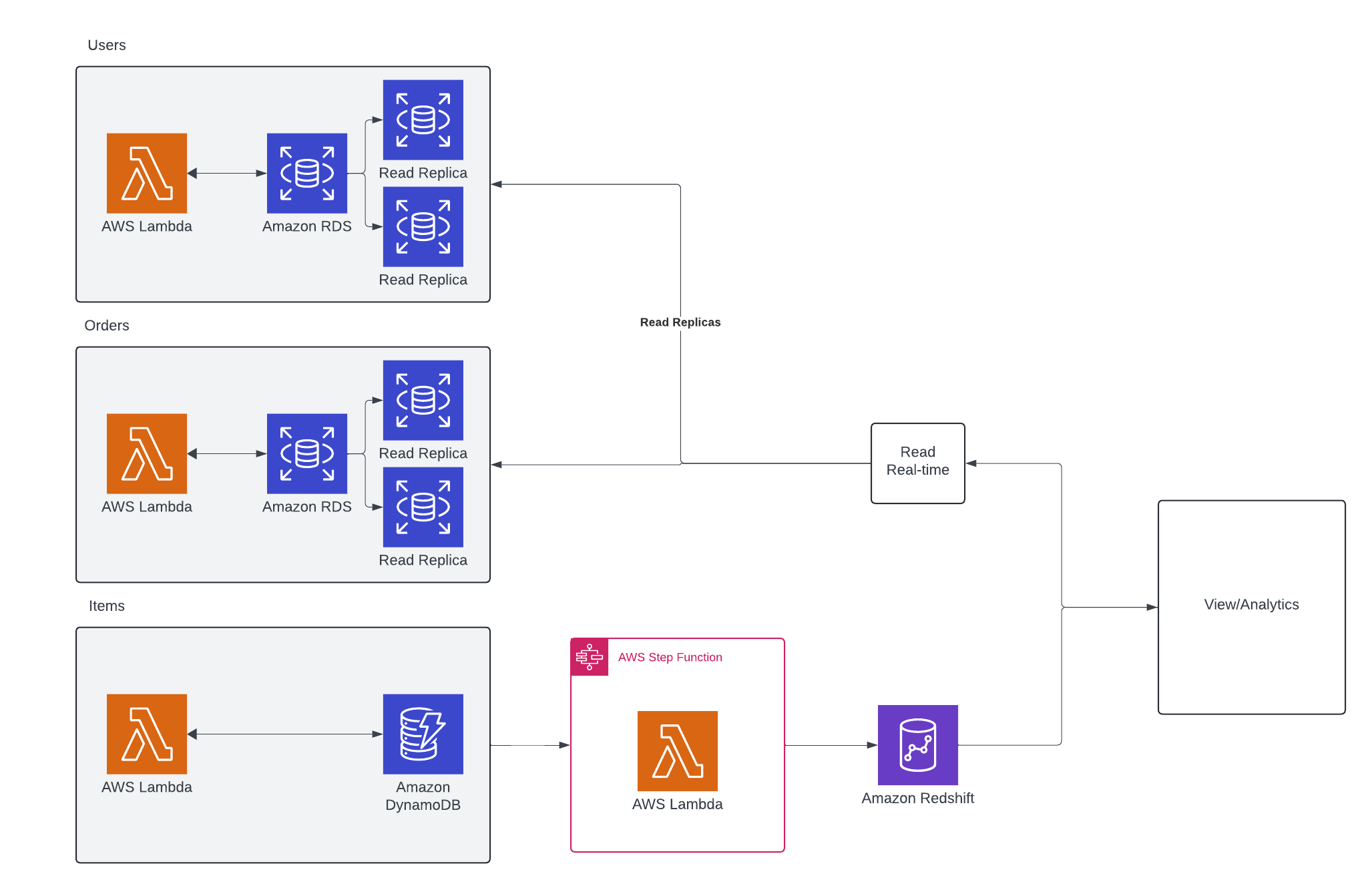
With this pattern, the system can make the best of both worlds. For scenarios where the data is stored in an RDBMS, make use of the techniques highlighted in the Replicate to Read pattern. But for data stored in something like DynamoDB, I’m introducing the notion of streaming changes, transforming them and ultimately landing them in AWS Redshift.
There’s plenty to unpack here that is outside of the scope of this article. Topics like, why Redshift? Should it be DDB Streams or straight to Kinesis? Why not EventBridge Pipes? And many more that could come up. However, I want to focus not on the implementation but more on the pattern. And that’s handling DynamoDB changes that are transformed into a system that provides the query flexibility of SQL.
Pros
Using the Split for Read and Speed pattern is great for solving reporting with serverless where there is a mixed mode of database storage technologies. The main advantages of this pattern are these:
A nice balance of speed and storage. For the RDBMS stored services, the same advantages from the Replicate to Read pattern are gained. Speed is enhanced because the data sits right next to the source. And then data that is stored in NoSQL can be streamed in pretty much real-time for live processing before landing in something like Redshift which provides that SQL implementation that mirrors that of the other sources.
It also allows some splitting and leveraging of best-in-breed technologies for solving problems. Developers can take advantage of the transactional and serverless features of DynamoDB while the reporting team can then use tools and technologies that are more familiar when building out reports. Again, a common SQL language for the reporting team is super important.
Cons
This pattern still struggles with the same ones that the Replicate to Read pattern does.
Connection management and data transformation is still encapsulated in the reporting tool. Depending upon the application size and number of services, this might not be a huge issue, but is something to look out for.
Additionally, another set of steps has been added to support the transformation of Documents or Key/Value items into relational rows. Honestly, the bigger the system, this is inevitable in my experience. And it will be more apparent in the last pattern below.
Lastly, there is a lack of extensibility that shows up in this pattern. Data is stored on purpose for reporting. That’s great if that’s where the journey ends as it relates to reporting with serverless, but there often is more to be accomplished.
Wrap Up
I find that this pattern is a nice blend for a lot of applications and might even be the starting point if the application uses no RDBMS technologies. The truth is, that a lot of modeling can be done in DynamoDB for reporting. Especially if the use cases revolve around single-item views or analytic-type calculations. But remember, all of that needs to be defined upfront. I haven’t worked on a project in my career where the product team could define all of the reporting requirements upfront. Which is why SQL is so heavily used. It allows for this dynamic packaging of data that is often required.
Eventually Readable
Eventually Readable is the most flexible yet not the fastest pattern when working on reporting with serverless.
I tend to reach for this pattern when my primary goal is Extensibility.
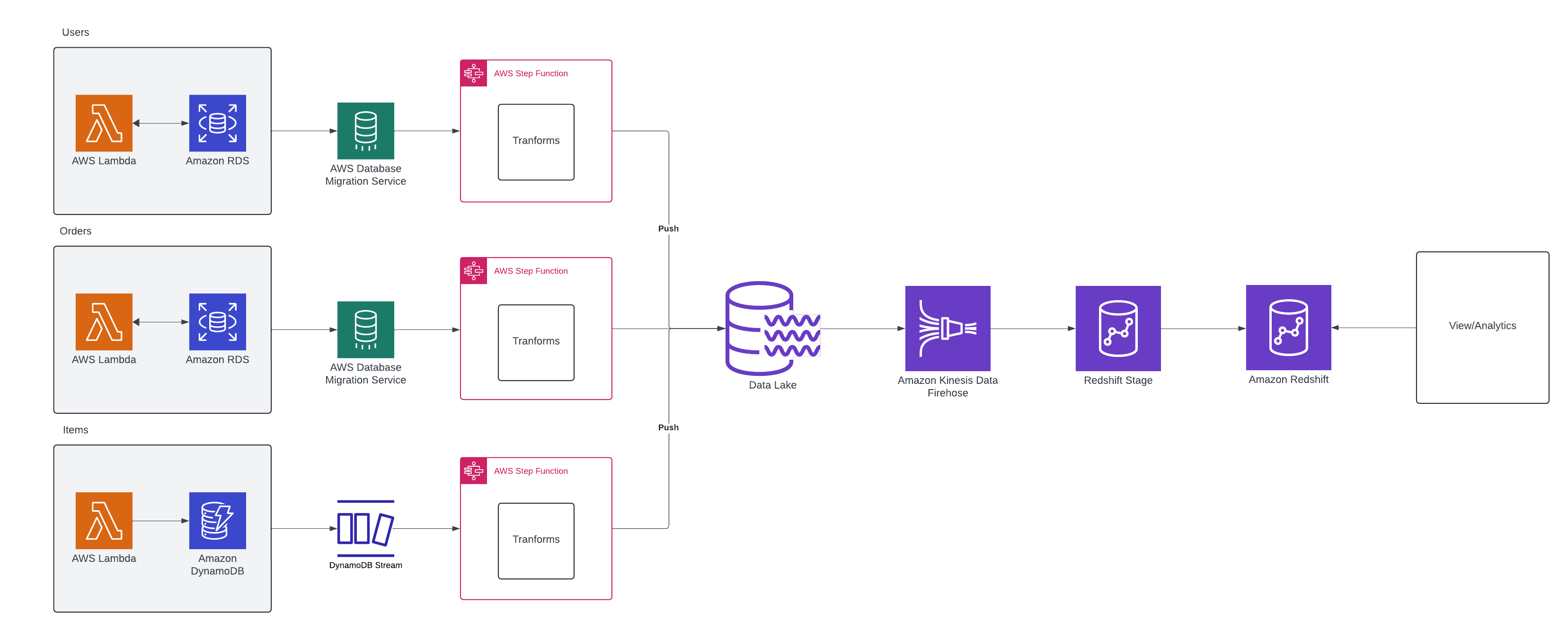
The data will ultimately land in a data lake that allows for so many additional use cases such as outside data blending, exploration, machine learning, and of course reporting.
It also allows me to split workloads out and then almost reverse the microservice flows into isolated team flows. For instance, there could be teams of analysts working on just users and orders. There could also be a team working on orders and items. Having the data fully unified before doing any of that work can then create specialized areas and patterns for further making information.
Before you want to go all in though, I will caution it comes with the most complex price tag. It also turns the data pipeline problem into an engineering problem. I wrote about that here. You will see some interesting parallels between the teams building user applications and the teams building data applications. Pairing this with serverless elevates the problems to a standard set of capabilities that allows for a great deal of cross-team collaboration.
Pros
The pros for this pattern center around ultimate flexibility. Once the data is unified in the data lake, the possibilities are truly endless.
Want to do some machine learning? Great, hook up SageMaker. Need something queryable in SQL? Awesome, stream with Firehose and straight to Redshift via the COPY command. Need more data than your system provides? Cool. Load it via another process not documented in that diagram.
I want to stress that this flexibility is the reason that this pattern is used.
Secondarily though the pattern starts to carve out more specificity in the roles that are needed to accomplish the design. The real-time transformations are engineering problems that will require serverless engineers. The data lake curation falls squarely into a data analysis bucket. And then preparation and schema modeling when doing reporting is squarely a business intelligence architect.
Remember, this flexibility comes with complexity which leads to the cons.
Cons
Two main cons come with this pattern. I mentioned in the above, complexity. More things can go wrong here. For each of the orders, items, and user services, there needs to be real-time transformation that lands the data into the lake.
The second big drawback is speed. There will be more latency in this scenario. How much latency depends upon the environment. If there is RDBMS in the source, AWS Data Migration Service will at worst take around 60 seconds to replicate. That cost needs to be accounted for. Secondarily, many triggering events are leveraged which happen fairly quickly but they do add up.
Lastly, depending upon how the data lands in something like Redshift, a Firehose COPY command from S3 does buffer before writing. Again, latency.
It’s always a balance.
Wrap Up
Solving for reporting with serverless using the Eventually Readable pattern comes down to how much flexibility is desired and balanced against latency and complexity tolerance. This is why technology is so fun. Everything is a trade-off.
Reporting with Serverless
Serverless is about the composition and extension of capabilities that expand and collapse with usage. When thinking about reporting with serverless, it makes sense to use the same architectural principles that are used to build applications in the data and reporting space.
I’ve seen people have modern serverless applications only to cripple them with traditional ETL processes and patterns for dealing with reporting. I’d challenge you to think differently and lean into the skills you are already building and using on the application side.
Wrapping Up
Be kind to your reporting friends when building applications. In my experience, report developers are often struggling with changing requirements, fickle users, data inconsistencies, and many other challenges that for application developers seem out of sight out of mind. But if you think about it, reporting with serverless is harder because of microservices. If everything was still in a monolith, many of these problems don’t exist.
At some level, we’ve caused these problems so it only makes sense that we help our friends solve them.
Start with these patterns and then evolve from there. There is plenty of room for variation and adaptation as well.
- Replicate to read
- Split for speed and read
- Eventually readable
My hope here is that I’ve brought some awareness that application development makes report development harder when adopting microservices. But by using the techniques used to build serverless applications, we can make things whole again by adopting those techniques for reporting with serverless.
Thanks for reading and happy building!


