

Building Serverless applications can feel a bit overwhelming when you are first getting started. Sure, Event-Driven Systems have been around for many years but this notion of using managed services to “assemble” solutions vs a more traditional “plugin” style architecture might throw you for a loop. Continuing in the series of Building Serverless Applications with AWS, let’s have a look at the “Debugging and Troubleshooting” aspect.
Series Topics
- Data Storage Choices
- Building the Application (Fargate/Containers vs Lambda)
- Handling Events
- Exposing the API (if there is one)
- Securing it all, including the API
- Debugging and Troubleshooting in Production
Building Serverless Applications – Debugging and Troubleshooting
If you’ve been following along with the previous five articles, thank you. I haven’t tackled this notion of a series before, but I felt compelled to pass along some of what I’ve learned over the past years in hopes that it helps you as you are beginning your serverless architecture journey.
Topics on Observability
Before getting started, I want to lay out a few topics that we need to cover in this article.
- What is observability?
- Logging is your friend and the way you log has an impact on your ability to troubleshoot. That includes context, content and the appropriate level
- Traces coupled with logs are a mighty powerful ally.
- Events happen fast and they move rapidly through your system, put a plan in place to be able to trace them.
- Metrics and alarms can let you know about issues before your customers do.
- Putting it all together
General Advice
Now that I’ve covered what we are going to explore I first want to lay out some general advice. This article is not exhaustive. And how you implement some of these techniques will vary based on your skills, your team’s skills, the tools you have and most importantly what matters to your application. If you start with Logs, Traces and Metrics you can’t go wrong. And if you stick to standards (which are coming along quickly) you can potentially avoid any platform lock-in that sometimes comes from this space.
Let’s begin.
What is Observability
So this is my definition of what that means:
“Observability is the ability to measure a systems’ state at any given time, understand how it’s performing and behaving and provide the right level of visibility into each operation in the event it needs to be inspected”
Visually it looks like this:
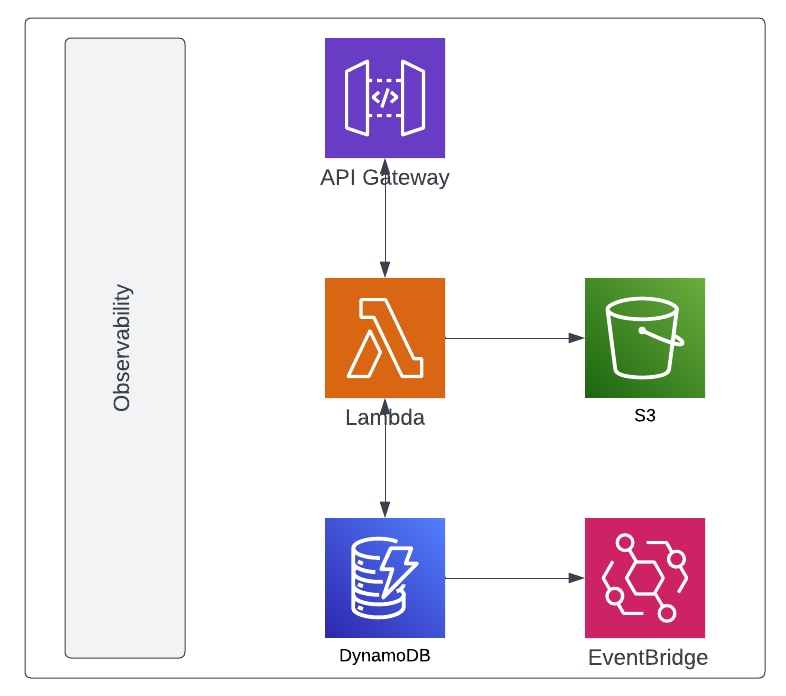
The point that I’m trying to drive home with that picture is that observability must be instrumented at every level of your application. Nothing comes for free and it will take work to put the right instrumentation in place, but the bottom line is, your system will be easier to operate and you will have the ability to respond to challenges as they happen in real-time.
Without the right instrumentation, you’ll be flying blind so to speak in that you will always be responding to issues and trying to determine what happened vs being able to have the insights you require to make the right determination.
Logging is your friend
Why should I care about logs? Simple. They are markers in your code that can emit any specific detail you wish at a specified “log level” to be collected and aggregated.
Log Levels
Most developers when they start programming will dump things straight to the console or standard output. While this can be a good place to start, you miss the ability to add context as well as control what gets outputted based on log levels. Levels will help you control the volume of output that is generated from your code.
So while the below will get the job done, the second code snippet is preferable.
// stdout
fmt.Println("this is a log message")
// logging library
logrus.Debug("this is a log message")
The most common log levels in logging libraries are as follows. FATAL, ERROR, WARN, INFO, DEBUG, TRACE, ALL.
Again, these matter because they help you organize your messages based on the severity of the message. I strongly recommend that you set a LOG_LEVEL environment variable in your Lambda or Fargate task definition.
I use something like this often in my CDK code to determine the logging level.
export const getLogLevel = (stage: StageEnvironment): string => {
switch (stage) {
case StageEnvironment.DEV:
case StageEnvironment.QA:
return "debug";
}
return "error";
};
Log Context
Now onto context and format. 5 years ago, JSON as the format seemed strange to me as it seemed super verbose so I often wrote parsers to split the logs as they landed in the log aggregator. Now, most logging aggregators prefer JSON and can extract fields from the context to add more capabilities when searching and filtering. I’d explore this with whatever log aggregator you are using though to be certain.
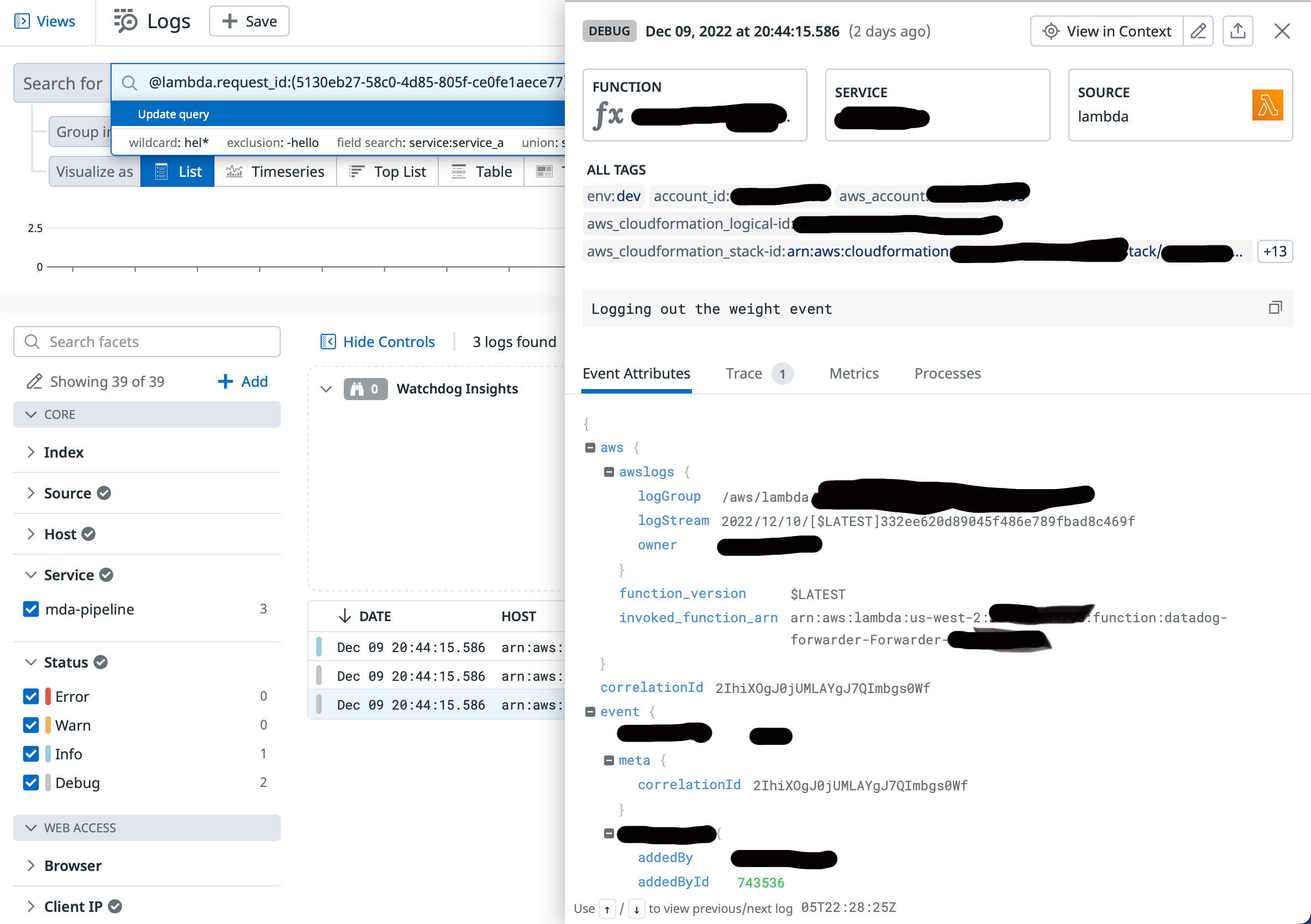
Notice in this screenshot from Datadog, you see the log message and can also see the context of the payload in my message itself.
The same thing happens in AWS Cloudwatch.
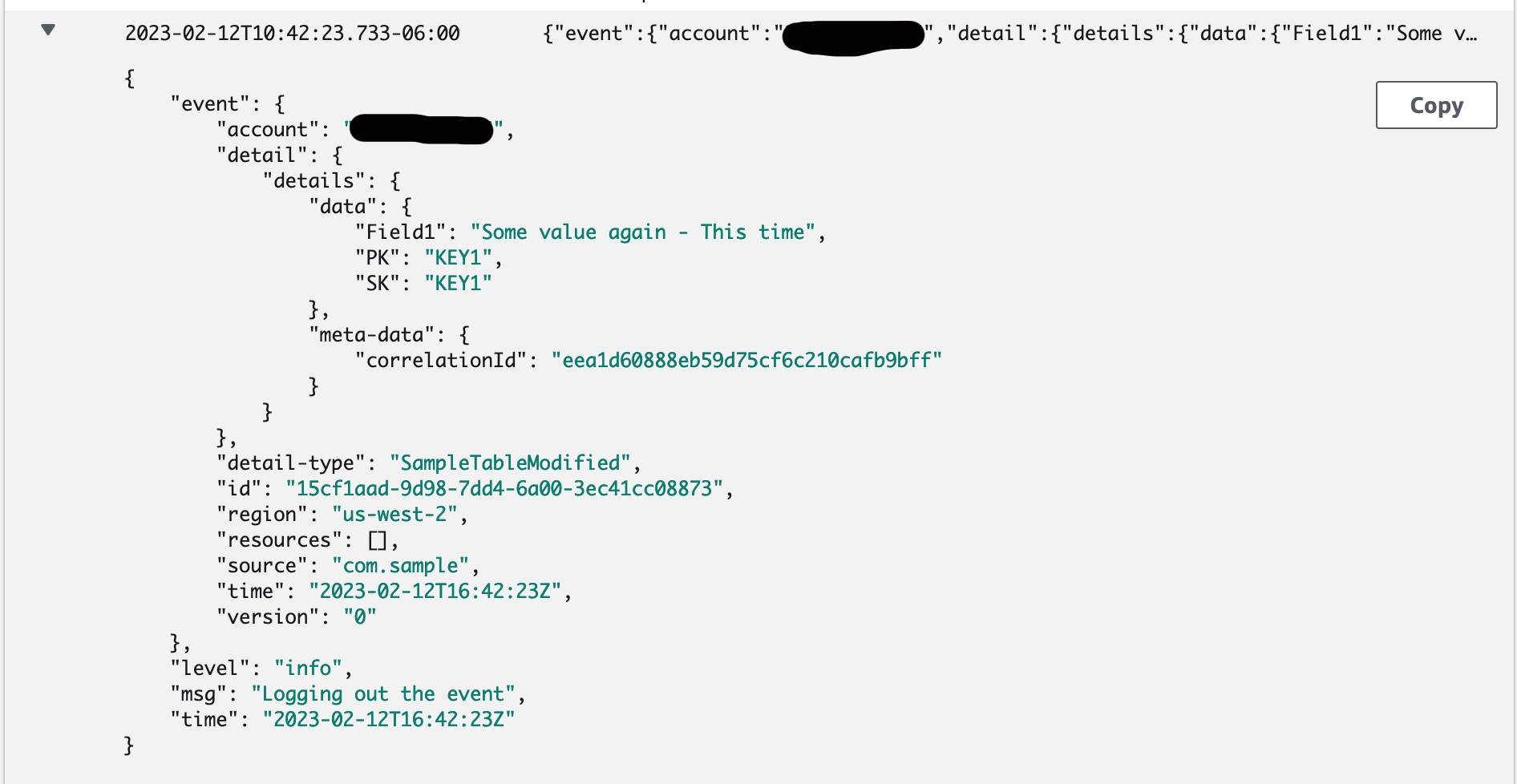
Adding context is a huge saver of time. Imagine you want to include your customerId, the userId or some other marker with the message. That makes those fields searchable, can be used in metrics (which we will talk about later) and filterable when drilling into what might have happened or be happening live.
Tracing those Requests
Traditionally, a request meant something coming from user interaction. But in an Event-Driven world, the request could be the processing of an event or a user request. Logs are one part of the story as they provide context into code execution. But traces gives you the ability to inspect the path/routes that your code follows and the timing for each of those traces. Traces can then be further subdivided into spans. Spans make up a trace.
For instance, one single Lambda execution might have a DynamoDB query, some custom logic and then push a message to EventBridge. In a black box, you’d only know about a single request. But by instrumenting your code to capture spans in a trace, you can then have ultimate visibility into your executions. This can be powerful if you are looking to debug a slow execution. Or it might be that you were unaware a code path was being executed as frequently as you expected. If the code path had a log statement attached to it, you could then further see what data was triggering what execution.
Pretty powerful right???
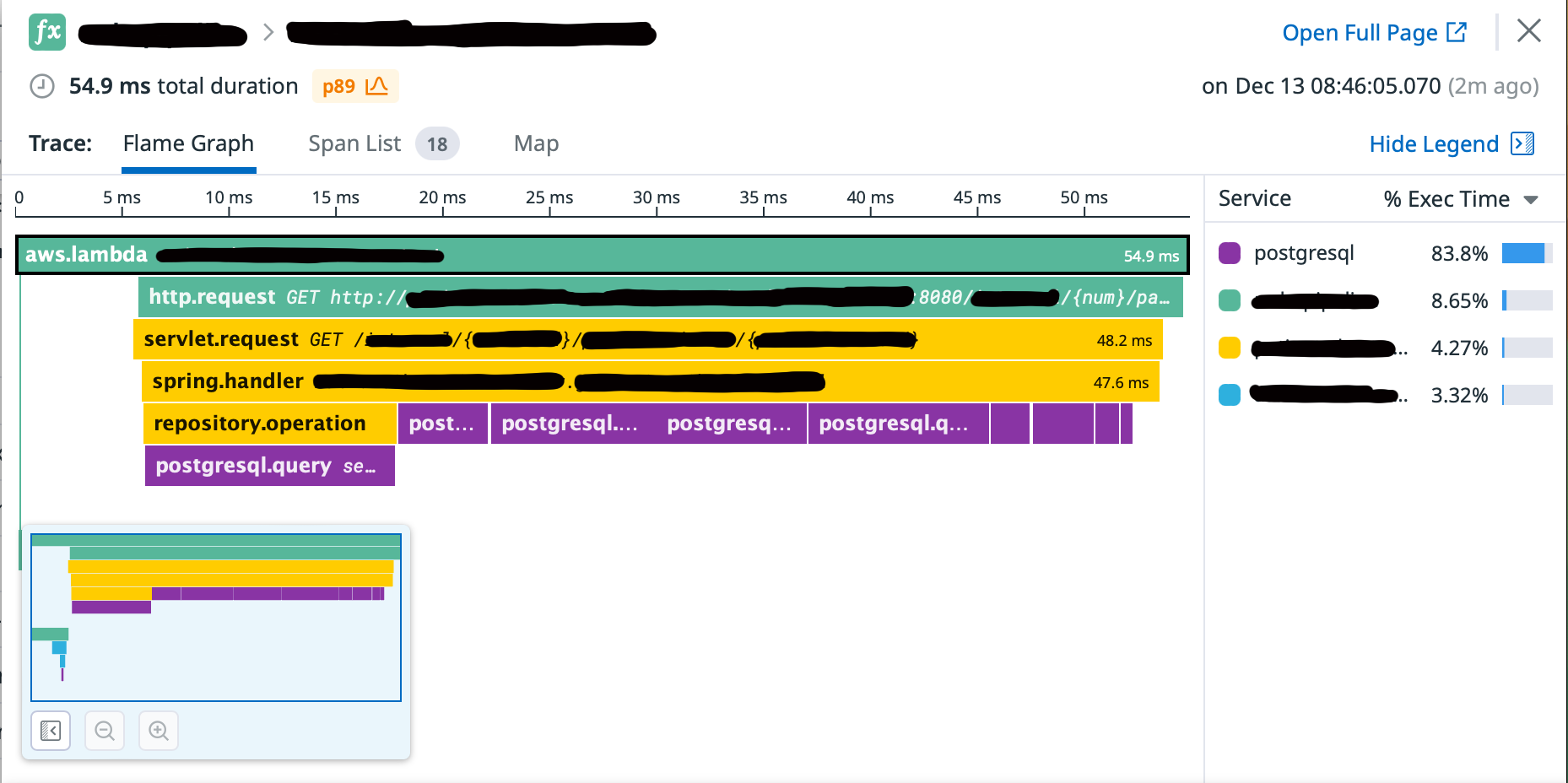
As everyone that’s been following along knows, I’ve been a huge fan of Datadog for some time, so these below screenshots show you how those traces come together in Datadog accompanied by some Go code.
This is an example of a Lambda that makes some requests to a Spring Boot Docker Fargate Task to refine a message.
And this is a simple Lambda that queries DDB and then puts a message on an SQS Queue.
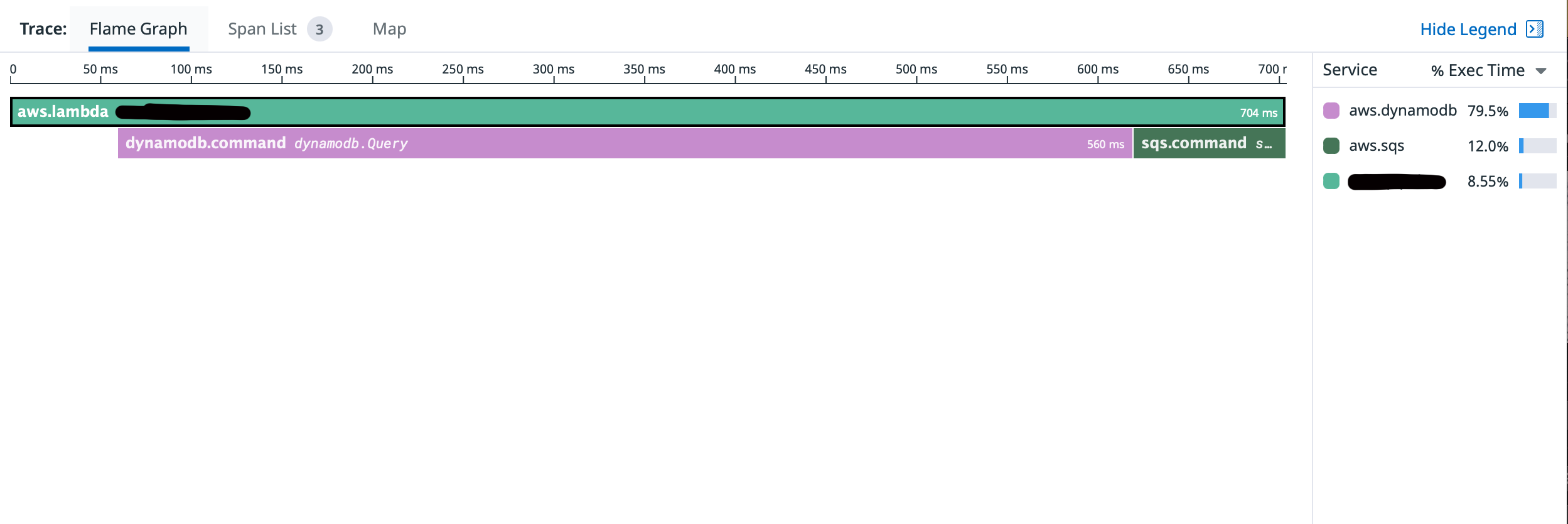
Connecting Traces to Logs
As I mentioned far above, this doesn’t come “for free” but with the right instrumentation, I hope you see the power in traces. But let’s take that one step forward. What if, you wanted to connect a specific trace to a specific log? Meaning, a path or execution you weren’t expecting could be identified by a well-placed log message. Again, leveraging your tool of choice (mine being Datadog), you can make that a possibility.
The below code will attach a Trace and its Span to this Debug Log statement and also print out the Event that was passed into the function.
span, _ := tracer.SpanFromContext(ctx)
newCtx := context.WithValue(ctx, "correlationId", ksuid.New().String())
log.WithFields(log.Fields{
"event": e,
"span_id": span.Context().SpanID(),
"trace_id": span.Context().TraceID(),
"correlationId": newCtx.Value("correlationId"),
}).Debug("Printing out the event")
Trival, yes. Powerful? Also yes. Those same spans can now have their logs attached to the view.
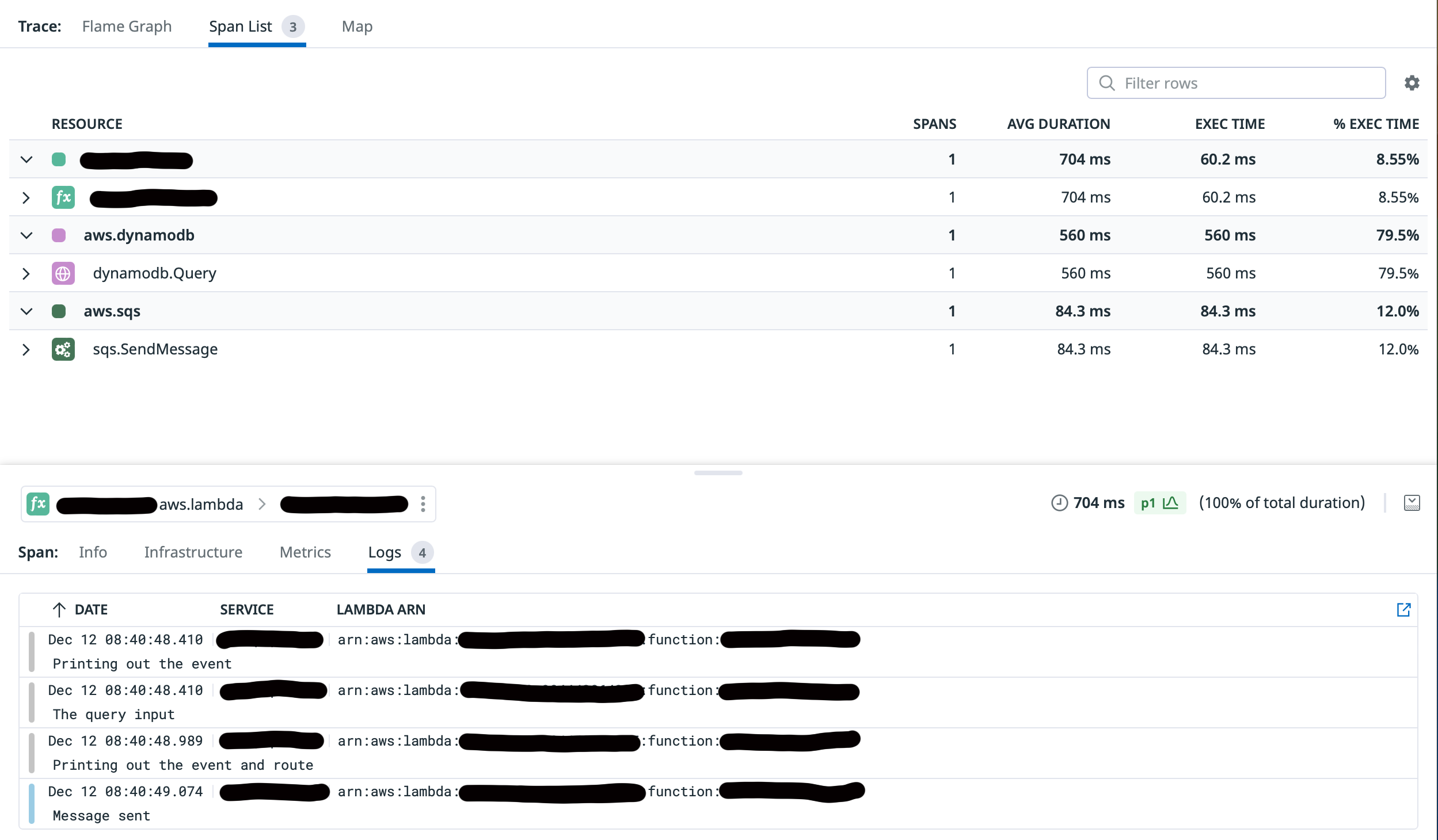
For full disclosure, you don’t have to connect logs and traces for traces to be useful. Traces will help you evaluate code paths, timings and what’s executing in your code. But when connected to logs, you’ll have insight that is like 1 + 1 = 3 where combined they give you a multiplier on being able to troubleshoot and debug your applications.
Events Happen Fast
The beauty of all of the services we’ve talked about in this series is that they work extremely fast and do their function with crazy efficiency. The bad thing about that is you could have 1 event with 10 + consumers all stemming from one user request or DynamoDB stream event. How in the world do you possibly keep track of that activity?
Enter the Correlation ID. This is by no means my idea but when done correctly will give you some amazing power to bring traces and logs together by a single identifier.
Imagine this. A user gets an error in the UI of your application. Now the user calls into your support system. How in the world (unless you have one user) are you going to be able to find their specific transaction and then all of the child processes that might be acting upon that single event?
At first interaction with your system, you need to be generating a Correlation ID that is carried from hop to hop and is in every log statement that you produce. A GUID, UUID, KSUID or the like will work just fine. If you are using AWS API Gateway, a RequestID is passed into your first handler. Use that. It’s simple and available. If your event is backend only, then the first compute should create the ID and pass that along as needed.
Correlation ID Tips
I want to leave you with a few tips on using correlation ids. You really shouldn’t be building distributed systems without them. You can also add them in as you go so if you’ve missed this point in your design so far, don’t leave them out going forward because you missed them. Start where you are and evolve.
Tip 1: I mentioned above the RequestID from API Gateway. But what if you have client tracing as well in your application upstream? Generate your ID in the UI, make sure your CORS setup allows the X-Trace-ID or whatever you want to call it and now you have tracing from UI -> last processing.
Tip 2: If using purely Step Functions on a trigger, use the Execution ID as your correlation id.
Tip 3: When DDB is triggering something downstream and your correlation id starts in the UI, add a column to your table for that record and just keep the last correlation id when saving so that it gets passed along in the stream. A tiny bit of coupling there, but it’ll be fine. The benefits outweigh the technique.
Tip 4: Give your message structures a meta section so that you are consistent with where you put the ID.
{
"meta": {
"source": "<source>",
"correlationId": "<id>"
},
"details": {
// insert the body
}
}
Metrics
Metrics are calculations across aggregations of logs or traces. What this might mean for you is that you want to pay attention to how many Requests contain a shopping cart value greater than $500. You can’t do that if you aren’t adding context to your logs with values on basket size. Or what if you want to pay attention to how many failed requests happen over a given timeframe. Or lastly, how many messages have accumulated in a Dead-Letter-Queue indicating failure?
All of those scenarios require you to correctly provide context in your logs and/or gather traces and spans. This is why understanding what you want to measure is so important. You can’t measure what you didn’t collect.
But what do you do with those metrics? For a base case, use them as a way to trigger an alarm. When failure gets too high, send an alarm. When a basket is that large, trigger a note to the customer welcoming them to your platinum service level.
I hate to brief on metrics but they make so much sense once you’ve laid the foundation which is traces and logs.
Putting it all Together
As much as I love AWS, this is the one area that I have chosen for my teams not to use their native tooling. Anecdotally, there are only 2 areas that exist for me that fall into this category. Observability is one. Caching is the other.
I could recommend you give Cloudwatch and X-Ray a try because they are worth a look. But for me, they just don’t give me the developer experience I want and the features like trace-to-log connectivity with a slick UI to navigate. I always feel like I’m jumping around tools to get most of what I need.
Datadog is my preferred
For my personal and professional work, I use Datadog exclusively to tackle the problem of Observability. And having written most of my Lambdas and Fargate Tasks in Go, I find I get a consistent experience between those two platforms. I’ve got an in-depth look at Lambdas, Go and Datadog at that link which I think would be worth you exploring.
When working with Lambdas you have a couple of options to make this happen. You can either use the Datadog-supported Lambda Extension. Of, if you prefer to have a Cloudwatch Log/Trace shipper, there is a Lambda function that can be installed in your account which will pull, parse and ship the same thing. I have tended to favor the Lambda Datadog Forwarder approach but the Extension route is also super solid. Here’s the Datadog documentation.
When it comes to supporting Fargate, you’ve got a few options on that as well depending on your language. But again, super straightforward to add traces and then using the supported fluent-bit image, you can route logs produced by your log library straight to your Datadog environment. Fargate Setup
Putting it all Together thoughts
I could spend a great deal of time walking through the advanced configuration of these setups, but as I started this series as a way to open your thought process and not prescribe a path, I think I should let you explore your implementation from here as this series comes to a close.
My takeaway for you though is that whether you use Fargate or Lambda, DynamoDB or S3, SQS or EventBridge, you can and should be tracing these workflows. And you can do this whether you use Datadog or not. I’ve been a huge fan of theirs for several years and couldn’t be happier as a customer as they partner so well with how I’m currently building.
To Be Explored Further
A quick note on portability. If you are concerned with vendor lock-in by any stretch, have a look at OpenTelemetry. This is the ultra-portable set of standards that you can build your foundation upon thus avoiding lock-in and having the right amount of abstraction to your observability strategy. I’m completely not doing OpenTelemetry justice but it’s something that you should explore on your own at this point and maybe something I do some further writing about.
Wrap up
So here we are. End of the line on the Serverless Summer Series, the place where I’ve tried to condense many years of experiences into 6 articles highlighting what I wish I knew when I got started. I hope I’ve accomplished my goal of not being prescriptive but opening your thought process and mind up to what’s out there in the AWS Serverless ecosystem.
All designs are unique and no one design solves all problems. The easiest way to always be valuable in an organization is to hone your ability to adapt and solve problems. Tech designs and trends come and go. They really do. But understanding your tooling so that you can solve problems for people and bring value to users will always be in trend.
That’s a wrap. And Happy Building!


