

I made a statement on LinkedIn that if you have enough traffic hitting your Lambdas you might want to consider a different programming language. And if you’ve been reading my content lately, you won’t be surprised that I suggested Rust as that alternative. Some great conversation and questions ensued with one of them suggesting that it would be less elbow grease to stand up Kubernetes with some pods than to improve performance on Lambda. The number thrown out was 250ms at the p75 mark. Fortunately, I had just the workload to test this out. Yes, I already know the answer and you should too at this point. But let’s dig in to Rust and Lambda Performance.
The Rust and Lambda Workload
For this Rust and Lambda workload, I wanted to do something super simple BUT useful. That embodies the spirit of Serverless. Simple is gold when building software and Lambda and Serverless shine at being able to isolate functionality into bite-sized chunks.
I recently worked with the Momento team to build out a Webhook Integration that posts to EventBridge. This handler was coded in Rust and exposes its functionality over a FunctionURL. To read more about the integration, follow that link. If you are curious about the source code that powers the handler, here is the GitHub repository. Doing things in public is so much fun!
So not to stress test Momento or AWS’ Lambda, I wanted to build a small but stable 10-minute workload that hits the Momento Topic API and then let Momento trigger the FunctionURL to run the Rust and Lambda code. I wrote a small Artillery config file that ramps up to 20 users and then sustains that for the duration. Again, the script is simple to trigger the work.
phases:
- duration: 60
arrivalRate: 1
rampTo: 20
name: ramp up
- duration: 1200
arrivalRate: 20
name: sustain
The Rust Code
Just lightly touching upon what’s in the Rust code, here is what happens when a POST hits the Function.
- Checks for a BODY in the payload
- Deserializes the JSON body into a Rust struct
- Verifies the BODY was generated within the last 60 seconds
- Uses a Secret stored in AWS Secret Manager to HMAC the request and verify the signature
- Publishes an Event to AWS’ EventBridge using the PutEvent API and the AWS Rust SDK
This is a pretty standard set of operations that I typically put in a Lambda. Again, it’s just a Function or an Event handler. It shouldn’t be huge. Here’s a deep link to the source code.
The Performance
So back to the original thought and the elbow grease.
First off, I appreciated the dialogue so much which is what spurred this post. My goal as an advocate for Serverless and the broader AWS is to educate. I want people to ask questions because it opens the conversation. And sometimes it’s hard to understand what’s real and what’s fake. And as a tech community we don’t always do a super job at being welcoming and inclusive. Something I also hope to just make a small dent in. It’s something that the BelieveInServerless crew is working hard to do as well.
Second, I’m not going to say always Serverless or always containers. Or always Rust or always TyepScript. I don’t think that’s helpful. But I tend to try and rule out Serverless first.
Onto the numbers!
Latency
Everyone wants to talk about latency and it’s actually what I started with too in the LinkedIn article. So how does this 4MB Rust bundle running with 256MB of memory handle latency?
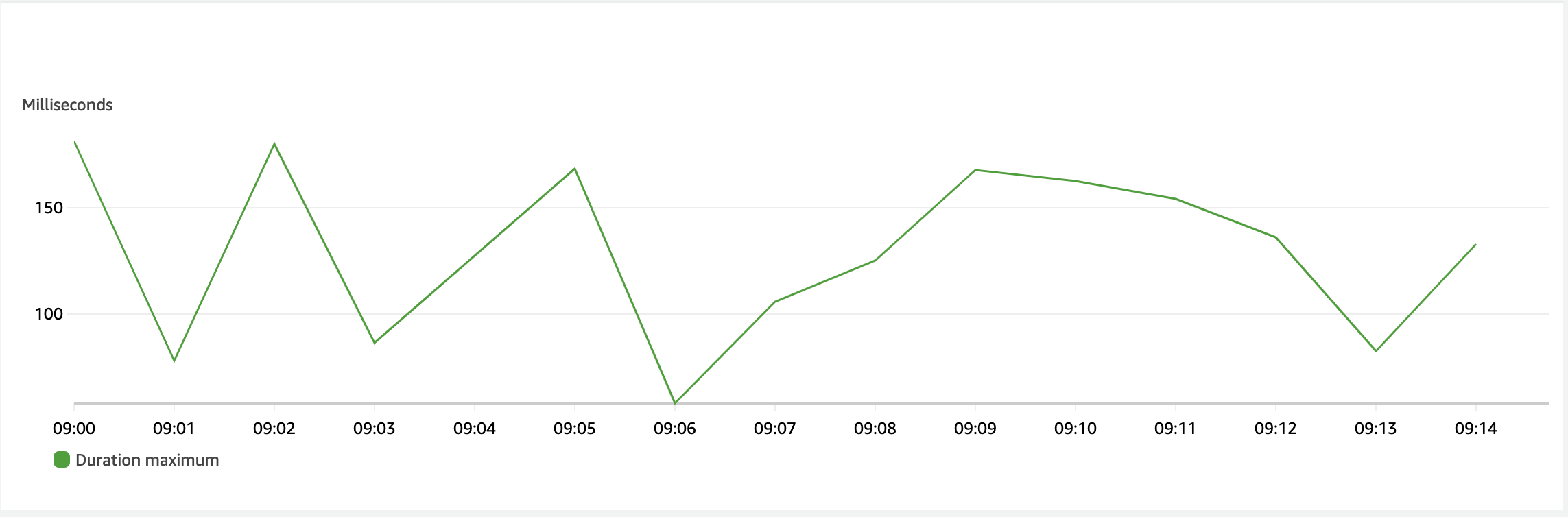
P99 – the cold starts
I’ve talked a good bit about tail latency with Lambda and those normally being the Cold Starts. The language, framework and bundle size matter here. So what does our latency show?
Over the 15 minutes that I measured the traffic, the highest recorded duration was 180ms. Right off the bat, we’ve beaten the 250ms mark by a nice number. I don’t have specifics because I didn’t trace the request but the majority of that time is initializing the AWS EventBridge SDK. I know this because I’ve seen non-SDK Lambdas start in less than 10ms.
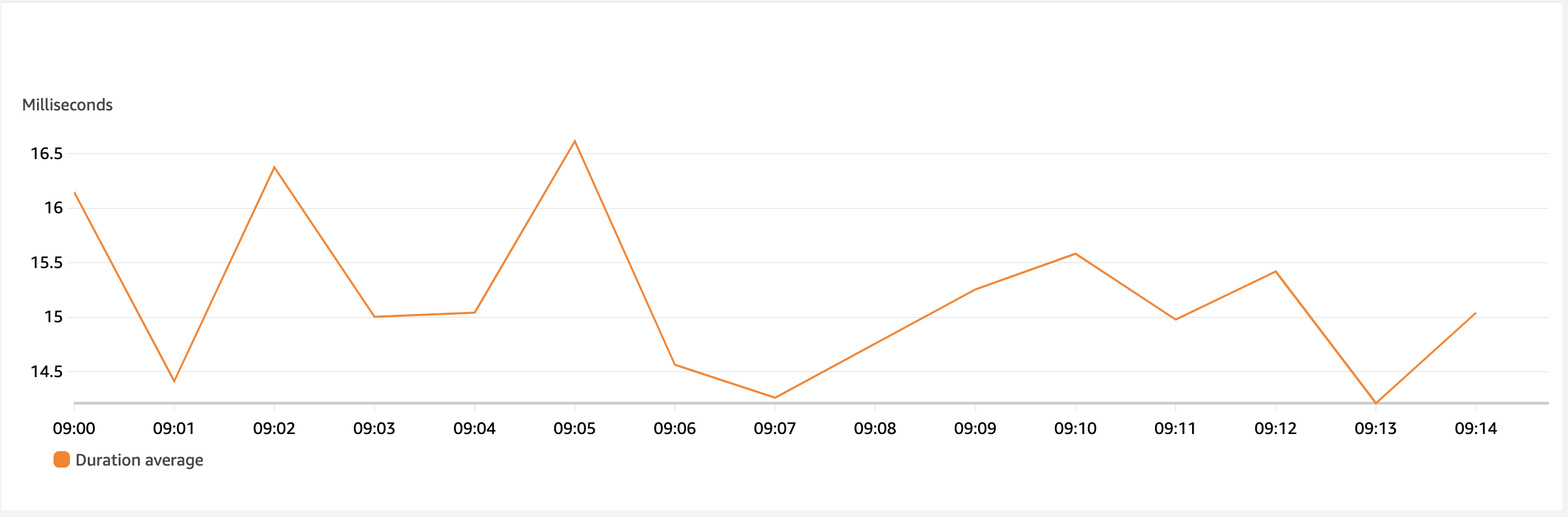
Average
OK, so we beat the 250ms number on the tail, but what does the Average latency look like?
The below graph is pretty powerful. The largest peak in that graph is 16ms. That’s roughly 230ms off the original ask of 250ms at the p75 mark. The lowest number is at 14.26ms which means we have a very smooth average performance. Incredible considering I’m not managing any of this infrastructure.
Back to the test, this is just steady and consistent traffic. If your load isn’t spinning up new Functions, you’ll likely not see that 180ms (p99) number again unless AWS decides you need a new runtime for some reason.
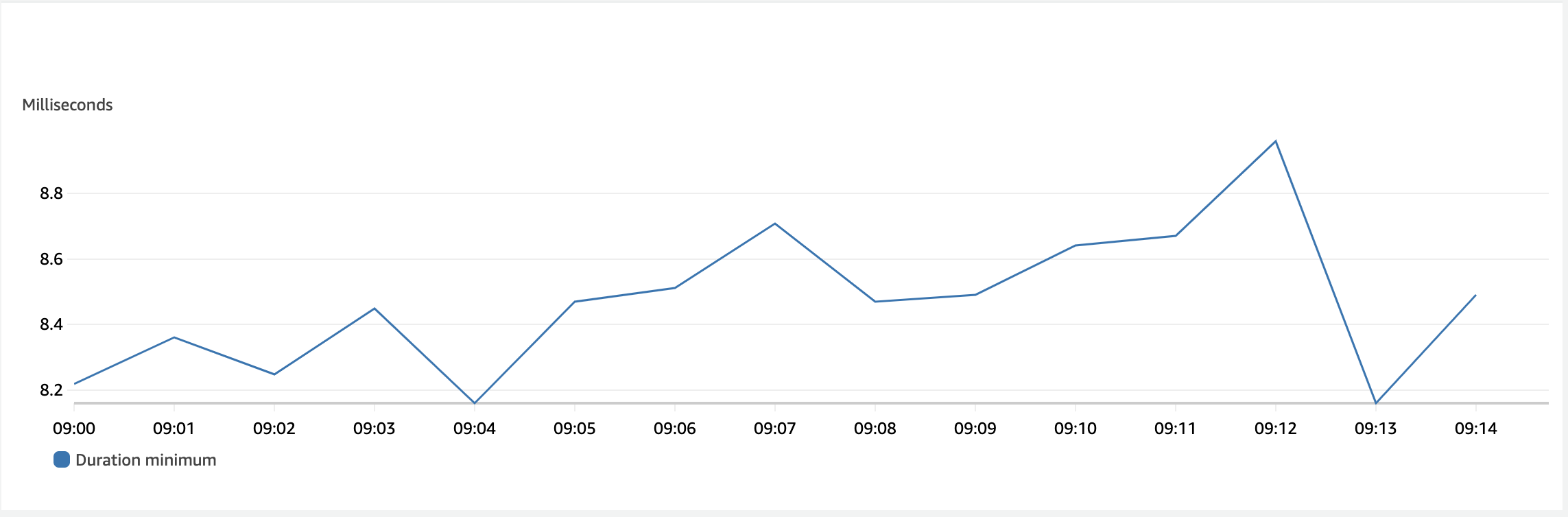
Minimum
Even though the number has already been beaten, I want to look at what the minimum duration a Rust and Lambda does over that same period.
This line would be flat if I hadn’t made the graph so tall. The maximum in that peak is 8.96ms and the bottom of the graph is 8.10ms. A non-noticeable difference.
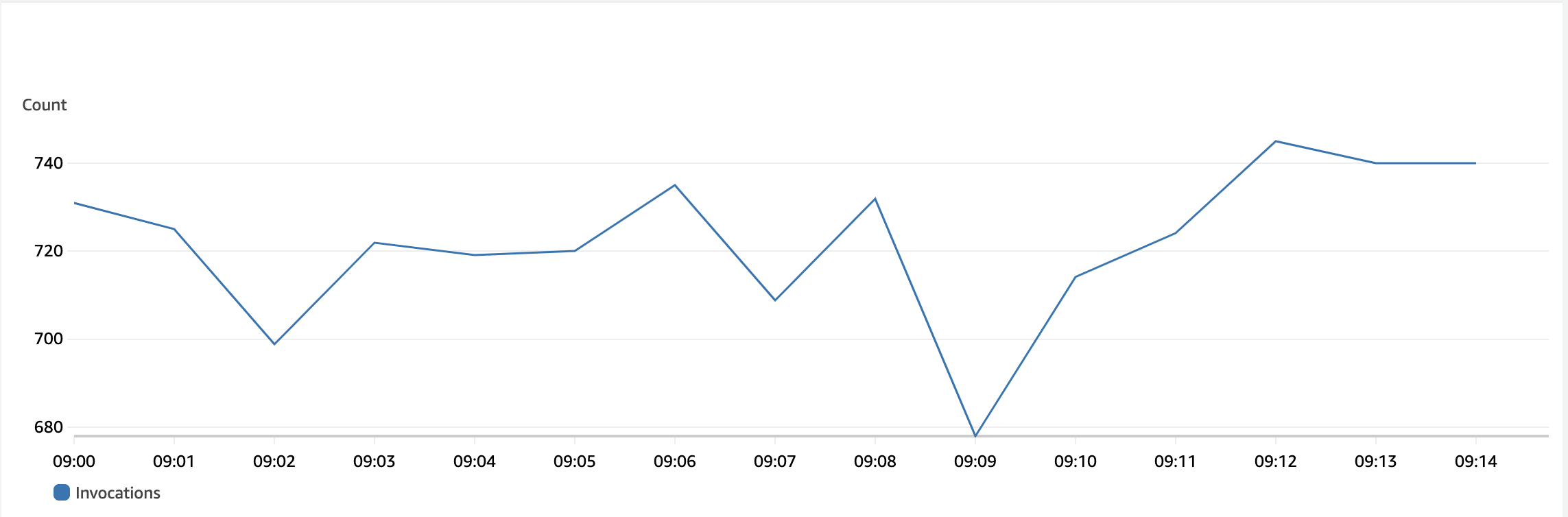
Invocations
I also want to show that the Rust and Lambda load stayed pretty consistent across the window of time. Invocations are just the number of times your Lambda has been triggered. There was a small dip at one point, but the traffic overall was steady. What I also find fun to investigate is the number of concurrent executions. I’m not going to show that graph, but the number stayed at 4 the whole time. This is useful to track as concurrency is a metric that means something at an account level.
Wrapping Up
How much elbow grease did this take? I worked with the Momento team for a few hours on the Rust and Lambda just to bounce threw requirements. So that was time I would have spent whether I was using k8s or Lambda so I won’t consider it.
I deployed the code this morning with the One-Click CloudFormation Template supplied by the article linked at the top. That took a total of 3 minutes to run. Setting up the Cache and Webhook in Momento also took about 2 minutes to navigate the website. And then I built the test harness with Artillery this morning as well in about 5 minutes.
Quite frankly the bulk of the time to do all this was spent writing this article and waiting for Artillery to finish. My elbows are chaffed and cracked like normal at the moment.
The last thing I want to offer here is that Serverless has a place in the value ecosystem. Is it the right fit for everything, no. But is it a great place to start a lot of the time? I believe so. And can you build highly scalable and enterprise-grade workloads with it? Absolutely! There are more than a few that have documented this well.
As for speed, looking at the 16ms average duration on this workload is plenty fast for so many operations. And when you layer in that the operational complexity and concerns are so much less than running your own, it’s a very attractive option for a lot of us.
Thanks for reading and happy building!


