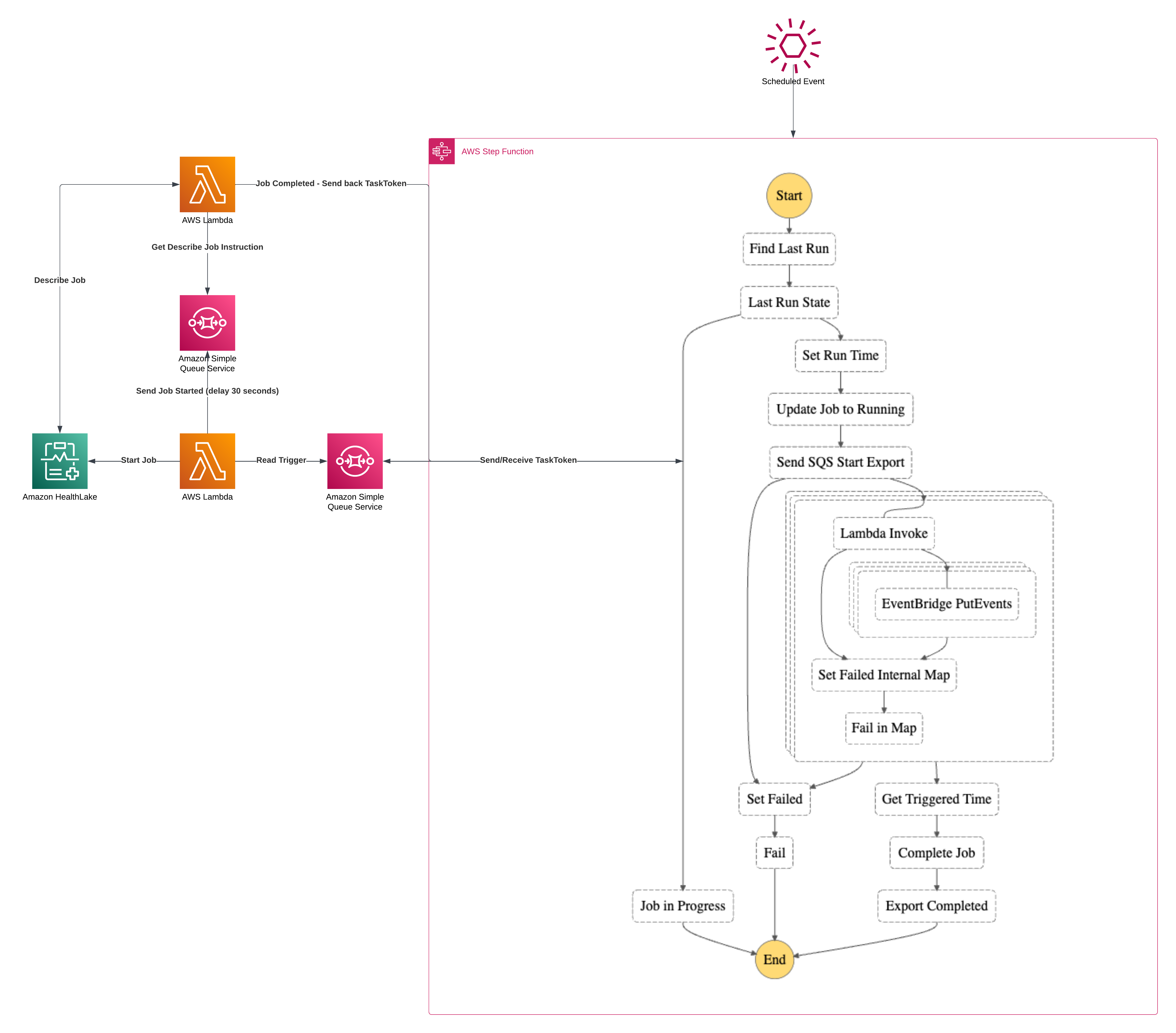
In my previous article I wrote about a Callback Pattern with AWS Step Functions built upon the backbone of HealthLake’s export. As much as I went deep with code on the Callback portion, I felt that I didn’t give the HealthLake side of the equation enough run. So this article is that adjustment. Managing exports with AWS HealthLake.
What is HealthLake
AWS HealthLake is a HIPAA-eligible service that provides FHIR APIs that help healthcare and life sciences companies securely store, transform, transact, and analyze health data in minutes to give a chronological view at the patient and population-level. – AWS
My words on that are that HealthLake is a FHIR-compliant database that gives a developer a robust set of APIs to build patient-centered applications. You can use HealthLake for building transactional applications, analyze large volumes of data, store structured and semi-structured information and build analytics and reports.
When building with HealthLake I find it fits in one of two places.
- As the transactional center for your Healthcare application. It is highly patient centered, very scalable and contains APIs for working with each resource. In addition, it provides SMART on FHIR capabilities that make it nice choice for building an application on top of.
- As the aggregation point for many external and internal systems in a LakeHouse style architecture for interopability and reporting. When you’ve got a distributed system with various datababases and you need your data reunited in one location. HealthLake does that. Or if you are pulling in data from various external sources, HealthLake can do that too. I wrote about doing this with Serverless a while back.